Upgrade from 1.5.7 to 1.5.8 issues
-
@Sebastian-Roth Possibly a global setting “Create dedup friendly image files” then if that global parameters are set it sets a kernel flag to tell FOS to add in the dedup command line parameters for partclone and image compression.
I don’t see a value in making this an image level option. You are either used dedup storage for your images or not. I don’t see a value in having image 1 configured for dedup storage and image 2 not. It should be all or nothing IMO.
-
@Sebastian-Roth I actually ended up removing the B128 option (https://github.com/FOGProject/fos/commit/e151e674b14279375884c8597e06f82272fe3f92) when I noticed some issues with it, so it’s not in the current inits.
The a0 option is to disable checksum creation, shouldn’t negatively impact speed either.
Although, it’s possible that the whole checksum thing is bugged, which is one of the issues raised at partclone by Junkhacker and somehow causing issues?
-
@Quazz Good point! Your comment made me look at this again. Now I see that I was too quick in assuming those changes were causing the slowness because all those parameters added are only used when creating/uploading the image. Seems like I had a too narrow mindset after hours of digging through this to not have noticed such an obvious thing.
The slowness I noticed yesterday must have been because of the removal of
--ignore_crcparameter in 3e16cf58 - while still using partclone 0.2.89 in this test. So test is ongoing. -
@Junkhacker @Quazz Looks like the
--ignore_crcparameter (discussed here as well) really makes the difference. Will do a test with the latest FOS build later today but a first run - exact same FOS one with parameter and one without - show the time difference. -
@Sebastian-Roth Can we add it as an optional parameter since it breaks compatibility with partclone 2 images?
-
@Quazz Ohhh well, how could I forget about this… Obviously there have been many other things nagging in my head this year.
After a long time digging into this things seem to add up at least. You mentioned the CRC patch in a chat session only a good week ago but I did not grasp it back then.
So now I manually added the patch mentioned to our 0.3.13 build and deployed an image (captured with 0.2.89) using the patched 0.3.13 partclone with parameter
--ignore_crc. Unfortunately this does not seem to fix the issue. I suppose it’s worth finding out why the patch doesn’t work instead of adding ignore_crc as optional parameter to the code. -
@Quazz Good news. I think I have figured it out. The bug described by @Junkhacker is not actually solved by the fix proposed I reckon - just udated the issue report.
Comparing two dd images of partitions being deployed one with
--ignore_crcand the other one without in a hex editor I found random bytes in the earlier one. Those looked a bit like the CRC hash is being written to disk instead of just skipped when we tell partclone to ignore CRC.Tests looking pretty good so far. Will build an up to date FOS init with added patches and
--ignore_crcadded for everyone to test tomorrow. -
@Chris-Whiteley @george1421 @JJ-Fullmer @Quazz Would you please all test this new init build: https://fogproject.org/inits/init-1.5.9-ignore_crc-fix.xz (very close to what we released with 1.5.9 but added
--ignore_crcoption and patches mentioned below)Web GUI issue? Please check apache error (debian/ubuntu: /var/log/apache2/error.log, centos/fedora/rhel: /var/log/httpd/error_log) and php-fpm log (/var/log/php*-fpm.log)
Please support FOG if you like it: https://wiki.fogproject.org/wiki/index.php/Support_FOG
-
@Sebastian-Roth
Just gave this a test
I’m on fog 1.5.9.3
I’m using bzImage 5.6.18
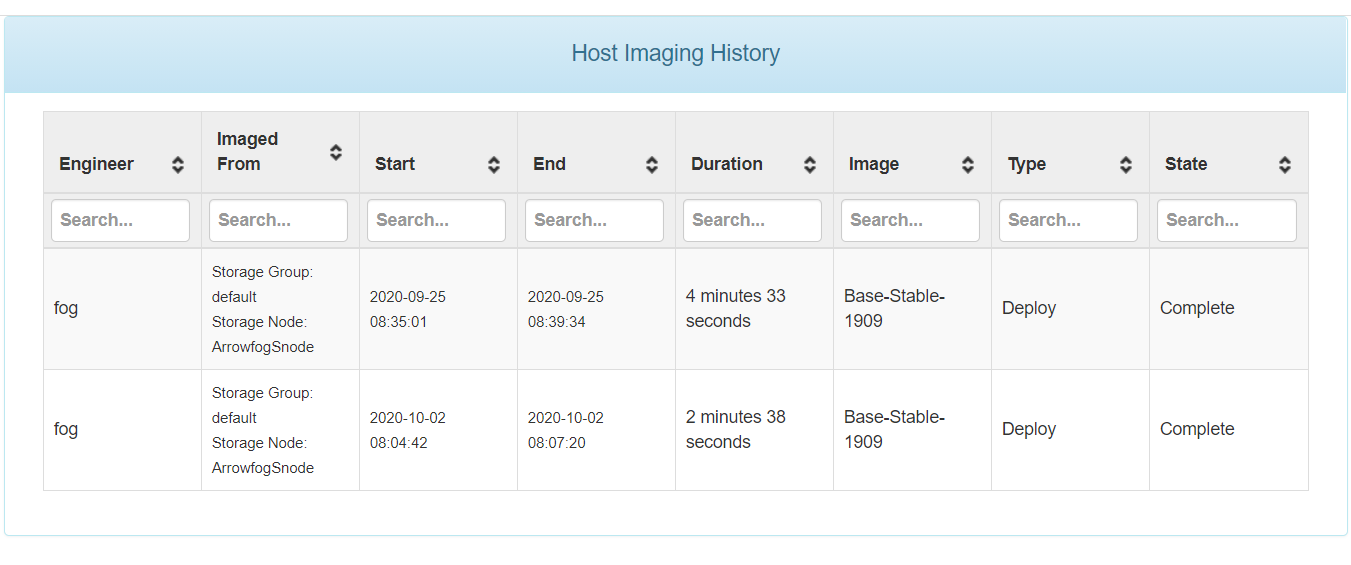
I set a host to use the init you shared.I had previously imaged this machine on the init that came with 1.5.9.3/1.5.9.2 and it imaged in 4 min 33 secs and when I watched the speed it was around 10-11 GB/min. But I wasn’t babysitting the speed, it probably slowed down a bit when I wasn’t looking based on the results below.
Same image on the new init didn’t appear to go much faster but did stay stable around 11-12 GB/min but it actually finished in 2 min 38 secs. So It almost cut the time in half.
So, I didn’t get to see the super fast 20+ GiB/min speed again, but it did finish in about half the time.
Edit
I also noticed it now shows speed in GB/min instead of GiB/min. Not that big a scale change, but something I noticed. I also deployed the image on the machine one more time, this time without being connected to a small desktop switch and got the exact same 2:38 deploy time.
Other Edit
I also noticed that I too don’t have any 2.89 partclone images to test. Mine are all 3.13 I’m pretty sure.
-
@moderators @testers I am still waiting for more people to test this and give feedback. Adding a manual fix to partclone’s inner core is only wise if we really know this really works!
-
@Sebastian-Roth Been very busy and don’t really have a great test setup right now.
Ran a quick and dirty test and get roughly 20% speed bump from the provided init over the one on the dev-branch. (ignore the exact numbers, it’s not very scientific, it’s a significant enough difference at least)
Seems to be roughly what was reported in here by OP from what I can tell.
I don’t have 2.89 images to test to see if they do or don’t work, however. That will be key.
-
@Sebastian-Roth Is it possible to detect if an image is made with partclone 2.89?
If so, we could just err on the side of caution to omit the parameter when we detect the image is the old style I guess.
-
@Quazz said in Upgrade from 1.5.7 to 1.5.8 issues:
Is it possible to detect if an image is made with partclone 2.89?
I have thought about this as well but I don’t see an easy way. The image file is usually compressed (gzip or zstd) and we need to unpack or pipe it through an “uncompress fifo” for any tool to read the header. Reading the header for distinction between different versions means that we cannot pipe that into partclone directly anymore I suppose. So we’d have to tear down the “uncompress fifo” and re-create it again.
I may ask why would we need to do this on the other hand? So far it looks like fixing partlcone properly would mean that we can deploy old and new images using partlone 0.3.12 I think. Though I am still waiting for more people to test this!
I know @Chris-Whiteley is very busy at the moment, but I’d really hope he and some other people get around to test the fixed init so we know how well it works.
-
Got a response from Chris about this. His tests were fine too and as we don’t seem to have anyone else willing to test I am “closing” this topic as solved now.
There has not been a response from the partclone devs either. I just just updated the issue and hope that we get this merged upstream as well.
-
Ok, let’s call it quits. I just pushed a commit to the fos repo to add this patch to our build of partclone and add the ignore_crc parameter back to the scripts.
Marking as solved.