[Seeking Volunteers] Bench Testing! Our trip to the best results!

-
Hi all,
Intro:
We’re currently extensively testing FoG and it’s capability’s. And since w’re doing it and gathering data, why not share and spare")
Sooo… now what?
Well… We’ve set-up a FoG Server with a test windows 10 deployment image (25gb). Our goal is to to define the best configuration set-up for FoG and network hardware.We needed to apply some configuration changes to our Cisco appliance to increase speed and packet size. i can image more users need to do so.
If anyone is interested we’re going to test some things and it would be great to be able to compare our results/config with others.
Bench testing what?
Since we’re not experienced with FoG, we will play around in some ways:
–Hardware and bios are exact. in our case. Dell T5810, Dell 3610, Dell 3600.- Best Deployment -type, protocol, compression, etc.
- Deployment difference -Deploying to direct system vs XCP-NG VM. in different settings
- Multicast: * Multi-casting from Master node (playing with storage groups) to external location through VPN*
We have our own environment set-up as test corner with it’s own appliance that we use in general. It’s a lot of details. Might be good to set-up a general environment criteria to avoid “dirty” and contradicting results… Feel free to reply if you have any idees or layouts
Goal:
- Map all criteria to reach highest deployment/capture speed.
- Define extra configuration requirements of third party appliance of FoG, such as Switch, Router, Firewall, Etc
Motivated by this wiki page
https://wiki.fogproject.org/wiki/index.php/Image_Compression_Tests
And by the replys –amount of devices the are managing with FoG
https://forums.fogproject.org/topic/4382/organizations-using-fog/107Hoping for a very active thread
<Fingers-Crossed>Cheers,
Mokerhamer - Best Deployment -type, protocol, compression, etc.
-
space holder for details! Comming soon
-
Though I like the enthusiasm, it may be my pessimistic nature talking, but I think there are too many variables to properly “benchmark” FOG. FOG’s claim to fame is how versatile it is, running on many different distros on very different hardware, going along very different network types and scales, etc. Even building a reference image can differ greatly. Unless you have the exact same type of disk (NVME, SATA SSD, Spinner) with the same exact version of the OS with the same procedure to set up said image, you will get the “dirty” results. So even if you have everything procedurally and hardware-wise replicated from test to test, you will only be bench marking that particular procedure and hardware. So if some other user with an entirely different setup was to look at your benchmarks without understanding this caveat and got different performance, he/she may think something is wrong. Just my two cents.
-
@fry_p
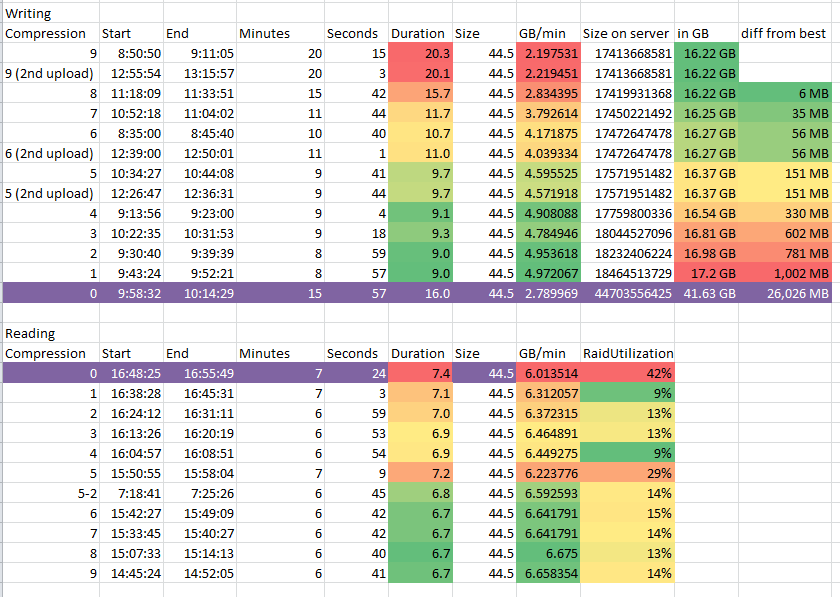
All True, i honestly hesitated to post (It’s complex to set-up…). But still lets share as much as possible.For example: Finding “goldilocks” Compression value for Partclone ZSTD.
For example: We made changes to our Cisco network to go from 3/4GB -> 5GB Deployment – 1/2Gb increase! Why not share the changes we made to our cisco appliance with hardware info so others can benefit?Rather to much information on forum then to few is my mentality.
-
@Mokerhamer I did do some initial benchmark testing back in 2017 and I documented it here: https://forums.fogproject.org/topic/10459/can-you-make-fog-imaging-go-fast
I can tell you based on an ideal setup on a single GbE network with one unicast image you should see about 6.1GB/m using a modern target computer. On a 10GbE network I would expect between 13-15GB/m transfer rates. On a well maintained 1GbE network you can saturate that server 1GbE link with 3 simultaneous unicast deployments.
AFAIK no one has done a study for a real comparison between pigz (gzip) and zstd compression settings.
Within the FOG imaging environment the deployment speed is directly controlled by the target computer. The target computer does all of the heavy lifting during image deployment. The FOG server and the network only delivers the image stream to the target computer. The target computer then takes the data stream, expands it and then writes it to the local storage medium.
For example I have a FOG server running on a Raspberry Pi3. I get 3 to 4 GB/m transfer rates on my home network. The bottle neck in this setup is the storage medium on the PI itself.
If you want to take on the challenge to see what is possible, everyone would be grateful for your efforts. Your testing needs to be scientific in nature. Using the same target computer, same network port, same, same, and only change one variable at a time.
-
@george1421 we did a bunch of testing to compare pigz to zstd back when we decided to include zstd compression in fog.
I had found the optimal setting for pigz in my environment was compression at level 6, and the optimal for zstd was level 11.
comparing those 2 optimal settings against each other.
zstd:
10% faster capture speed
26% smaller files were produced from capture
deployment was 36% faster.zstd was early in it’s development and adoption back then and has had some changes to actually improve on it’s compression and speed since those tests were done, but we don’t know exactly by how much.
-
oh, also, i disagree with george about how fast an “ideal setup” can be with a single GbE network and one unicast:
https://youtu.be/gHNPTmlrccMsignature:
Junkhacker
We are here to help you. If you are unresponsive to our questions, don't expect us to be responsive to yours. -
@Junkhacker looking into all messages. will reply soon just testing some things.
-
@Junkhacker are you using any 10gb network appliance? or 1gb?
-
@Junkhacker said in [Seeking Volunteers] Bench Testing! Our trip to the best results!:
oh, also, i disagree with george about how fast an “ideal setup” can be with a single GbE network and one unicast:
Boy, who made Mr. Hacker grumpy today?
")
While we all know this already, but the number show in Partclone (GB/m) is actually a composite score of network transfer rate, decompression rate, and the speed to write the image onto the storage media.
In a typical 1GbE network if someone said they were getting between 6.0 and 6.7GB/m deploy rate, based on my experience I would say that’s normal.
If we just look at the numbers, a 1GbE network has a theoretical maximum throughput of 125MB/s. In practice I see 110 to 120MB/s. So lets use 120MB/s x 60 seconds = 7.2GB/m. So a 1GbE link can only transmit a maximum of 7.2GB/m. So in theory its not possible to get a deployment rate faster than 7.2GB/m. Your video showed 10GB/m, how is that possible? That is because the partclone number is a composite number which also includes image expansion and writing to the storage media. If you have a fast target computer with a fast disk, the target computer can take that 7.2GB/m data stream, expand it and write it to disk just as fast as the data can get to the target computer.
Please help us build the FOG community with everyone involved. It's not just about coding - way more we need people to test things, update documentation and most importantly work on uniting the community of people enjoying and working on FOG!
-
@george1421 right don’t forget that the amount of data written too disk is much larger because of the compression ratio which is why the compression medium and speed of decompression is so important.
-
@george1421 all of what you said is true, but it just emphasizes the importance of benchmarking compression. with all of the variables that can come into play, the one thing you can usually rely on being consistent among peoples setups is 1GbE to the end client.
the maximum transfer rate on gigabit is well established, but what’s important is end result speed of writing to disk, and that’s what we can effect with compression methods.
btw, i wasn’t being grumpy. i just like to highlight how fast Fog can be. it’s one of Fog’s killer features that other methods can’t beat. (if anyone has seen a faster deployment method than Fog, please let me know.)
-
We’re currently around 15gb/s with unicast and 8 GB/s with multicast. Why almost 50% difference? so continuing with tweaking and figuring out some things.
Would there be difference between a small 24gb image or one of our large 300gb+ one?
-
Imaging speed is determined on Stream->Decompress->Write to disk. (Technically the speed you see in partclone is purely the speed at which it’s writing to the disk.) However, this is limited to the amount of bandwidth in use to send the data.
As @george1421 showed, from a purely networking standpoint, the maximum would be 7.25 GB/min.
This is likely where you’re seeing a variance in the Unicast vs. Multicast.
I’m assuming in the Unicast instance, you’re sending the image to a single machine. So it’s got the full GB backbone available for network streaming. In the case of multicast, it floods your entire network (subnet basically) with the packets. It also has to keep a “steady” stream so the slowest machine in the group will be the entire limiting factor for all machines.
I’ll bet if you Unicast to 5 machines and Multicast to the same 5 machines, you’ll see a semi-evening out of the speed rates.
Please help us build the FOG community with everyone involved. It's not just about coding - way more we need people to test things, update documentation and most importantly work on uniting the community of people enjoying and working on FOG! Get in contact with me (chat bubble in the top right corner) if you want to join in.
Web GUI issue? Please check apache error (debian/ubuntu: /var/log/apache2/error.log, centos/fedora/rhel: /var/log/httpd/error_log) and php-fpm log (/var/log/php*-fpm.log)
Please support FOG if you like it: https://wiki.fogproject.org/wiki/index.php/Support_FOG
-
@Tom-Elliott said in [Seeking Volunteers] Bench Testing! Our trip to the best results!:
I’ll bet if you Unicast to 5 machines and Multicast to the same 5 machines, you’ll see a semi-evening out of the speed rates.
Only citing for reference: During my testing 3 unicast images would saturate a 1GbE link. So 5 would surely show the difference between multicasting and unicasting.
@Mokerhamer You also need to remember two things about multicasting.
- The speed of the multcast is controlled by the speed of the slowest computer in the multicast group. If you have a computer with a slow check in for “next block” that will impact the whole group.
- Multicasting is a different technology than unicasting. Muticasting relies on how efficient your network switches handle multicast packets and if you have igmp snooping enabled, and if you have the switches in pim mode sparse vs dense.
Please also understand that no one here is discouraging your testing. It is and will be helpful to future FOG Admin. Its an interesting topic that is why you have so much focus on your thread. Well done!!
-
You knocked it right on the head with the multicast details, took a few tries to get the all the details configured. We’re now thinking about setting up a 10GB network and do the exact same tests. just curious… what speed would we reach? especially with all the variables in play.
This is a pure trial and fail, find the limits. Fail uncountable times and still keep seeking for answers. We’re using something new with a very high compression ration and i find there is a limited information pool about it. So i am extra curious about pushing limits with this.
In my eyes these trial and fails can decide or break a future plan of our classroom hardware architecture.
-
@Mokerhamer said in [Seeking Volunteers] Bench Testing! Our trip to the best results!:
We’re now thinking about setting up a 10GB network and do the exact same tests.
What we have here is a 3 legged stool. On the one leg we have CPU+Memory, on the next leg we have the disk subsystem and on the final leg we have networking. Its always a challenge to see which way the stool will tip.
If you look a bit back in time at the target computers the disk subsystems were the bottleneck. They were in the range of 40-90MB/s. The CPU+memory has been fine from the speed side for many years as well as the networking had plenty of bandwidth.
Now look today we still have primarly a 1 GbE networking infrastructure to the desk, NVMe disks that can write upwards of 700MB/s, Fast and WIDE CPUs (multiple cores). Now the bottle neck is the network. It just can’t pump the bits down the wire to keep both the CPU and disk busy.
Moving to 10GbE will be interesting to see which leg will fail next. With 10GbE you will have a maximum throughput of 1.250 MB/s. On a clear network you “should” be able to saturate that disk subsystem again, assuming the CPU+memory can keep up with the network card and expand the data stream fast enough.
Make sure when you get it sorted out you share your changes on what you found so others can see the improvements you’ve made.
-
We’re having difficulties with the 10GBe network card on client.
We’ve Fully disabled onboard NIC on the system (Bios).
System boots PXE (TFTP/http)… but when it wants to mount FOG it suddenly said no DHCP on ENP12S0 nic. Like it’s expecting to receive DHCP on onboard nic. Dident expect that…
-
@Mokerhamer said in [Seeking Volunteers] Bench Testing! Our trip to the best results!:
but when it wants to mount FOG
Lets just be sure I understand correctly.
You can pxe boot into the fog iPXE menu. When you select something like full registration or pick imaging both bzImage and init.xz is transferred to the target computer. The target computer then starts FOS Linux, but during the boot of FOS, you get to a point where it can’t get an IP address or contact the fog server, it tries 3 times then gives up? Is that where its failing?
-
