Hi,
I’ve encountered some problems maybe related to the queuing when deploying a group of computers. The groups have a size of 25 and 31 computers and the problem occurs in fog versions 1.5.10.1615 and also 1.5.10.1639.
The problem is that all the computers in the group are starting fine by WoL, booting up PXE an then successfully enter the queue to start imaging but none of them are starting imaging and display:
“There are open slots, but XX before me on this node (in line for yy:yy:yy)”
- XX is a higher number between 18 an 31 as far as I could see. Lower , single digit numbers seem not to be present.
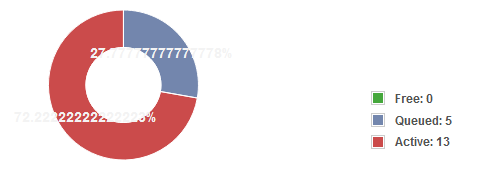
- On the Dashboard the status is like: Free: 0, Queued: 31 (or 25), Active 0
- Under Tasks all the Imaging-Tasks are there and have the Status “Checked in” (Pause symbol)
- in the database table “tasks” there are no other Tasks with the taskStateID 1, 2 or 3 except the 31/25 that should be there
- The Max. Client Size of the (only) main node is set to 13 and has been tried to set to 8 or 10 but no computers started imaging
The “workaround” to get it started is to force 13 computers manually by clicking the lightning button in the active tasks. Then the PCs are starting to get the image. What I could monitor:
- after 13 computers are forced to image the queued comupters display: “No open slots, There are XX before me” with XX now lower numbers stating at around 15 but no lower or single digit numbers as far as I could see
- in the group of 25 computers the last 12 automatically begin to start
- in the group of 31 computers the status after 13 finish is:
– Free: 0, Queued: 18, Active 0 but no new computers begin to start imaging.
–After forcing another 3 computers to start, additionally 3 begin to start automatically and the status is: Free: 0, Queued: 12, Active 6.
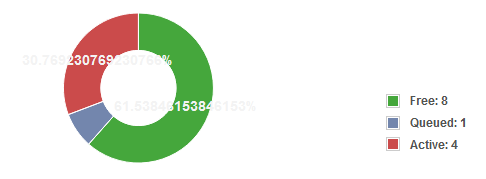
– Now the status is Free: 0, Queued: 0, Active 13 (witch seems to be normal)
– after finishing all the tasks the status will be Free: 13, Queued: 0, Active 0 again
Single computer deplyoment works just fine.
Any Idea what could cause this problem? The version (1.5.10.something - I’ll try to find out the version number) we used before 1.5.10.1615 didn’t have this problem.
Thanks.