Resize CentOS7 fails e2fsck
-
Re: Deploy image not expanding partitions
I’ve been using the fogproject to deploy windows images for some time now and thought I would attempt a linux deployment. I had already done so with a pxe via hand scripts and wanted to see how fog project handles it.
Initially I was quite impressed. I captured an image (one disk, 4 partitions and made it resizable). Capture went well and I was able to deploy on a few boxes. Now the image has been sitting for about 6-8months and I attempted to re-deploy. Yet now the deployment fails as it wants to e2fsck before resizing and I have no way of interrupting the process to do so.
Sadly I went back to my older method of deploying images. Once deployed I decided to re-capture it but this time use the non-resizable option. After the capture was complete I decided to re-deploy the image. The image deployed without any issues. As I still had the old “resizable” image I thought I would change images and redeploy again. This time the resizable image deployed without any issues.
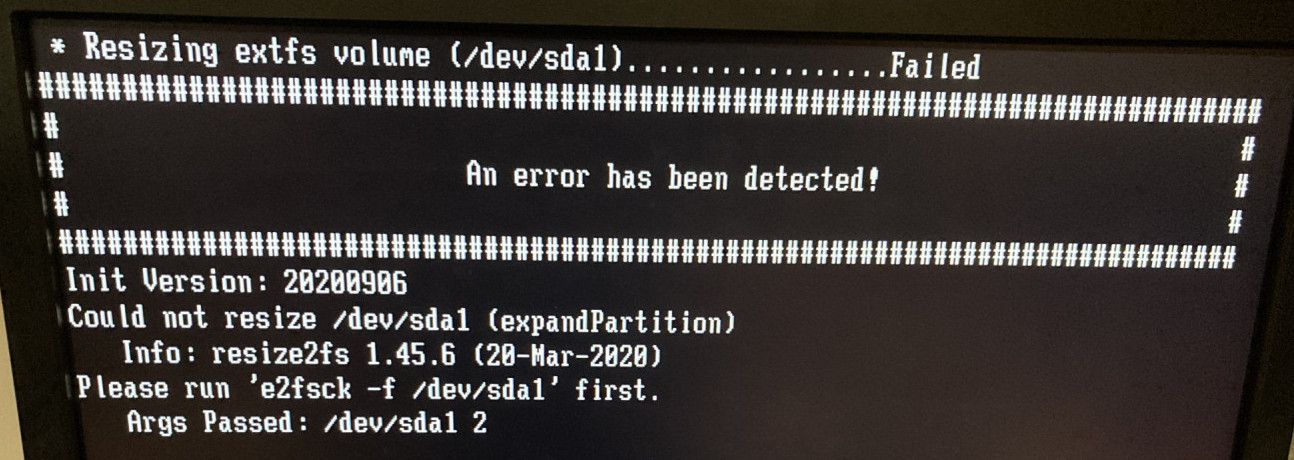
Still curious I pulled the drive and put another blank drive onto the system and attempted to deploy the resizable image. Again it failed to deploy saying: "Could not resize /dev/sda1 (expand Partition)
Please run ‘e2fsck -f /dev/sda1’ first…Please help me resolve this issue.
Just so your aware my fog server is a CentOS 7 box, running FogProject 1.5.9
-
@JasonNaughton Don’t think the issue linked is not related as it talks about a capture issue in a very old version of FOG. But yours is in deploy.
It’s very strange you get different results when deploying the exact same (resizable) image to the same host twice.
Were the two disks different size. Still shouldn’t cause this error. Just trying to make sense of it somehow.
Can you please do further tests on the same disks and see if the error popps up randomly or what!?
-
I know if I attempt to re-install the system with any disk, which is large enough to hold the image I will get the above issue. constantly now. I’ve put the system in debug mode and I’m attempting to issue the install commands by hand to see what the issue could be. I believe the issue either has to with the partition layout not being re-read into the kernel space. ie if I have a system that has no partitions, or the disk has existing partitions, yet different physical layout, and I deploy a realizable disk image it will produce this error. It’s almost as if I need a hdparm -z /dev/sda a few thousand times until the kernel recognizes the partition change and alters /dev
-
Okay so I’ve done the following debugging so far… The image that I created was called CentOS7-MBR, as it’s a MBR not a GPT installation. After letting the system boot via pxe and get to a fogclient prompt I referenced the URL:
Now unfortunately I’m dumping a linux image via partclone not a windows 7 image but I thought the process would be similar.
# dd if=d1.mbr of=/dev/sda bs=512 count=1 1+0 records in 1+0 records out 512 bytes copied, 0.0256039 s, 20.0 kB/s # partprobe # cat d1p1.img |pigz -d -c |partclone.restore -O /dev/sda1 -N -f -i Partclone fail, please check /var/log/partclone.log ! # ls -ld /dev/sd* brw-rw---- 1 root disk 8, 0 Feb 27 16:06 /dev/sda brw-rw---- 1 root disk 8, 1 Feb 27 16:07 /dev/sda1 brw-rw---- 1 root disk 8, 2 Feb 27 16:06 /dev/sda2 brw-rw---- 1 root disk 8, 3 Feb 27 16:06 /dev/sda3 brw-rw---- 1 root disk 8, 4 Feb 27 16:06 /dev/sda4So… not sure how to proceed. When I looked into the partclone log file it wasn’t much help:
# cat /var/log/partclone.log Partclone v0.3.13 http://partclone.org Starting to restore image (-) to device (/dev/sda1) read image_hdr error=0Any advice…
-
@jasonnaughton said in Resize CentOS7 fails e2fsck:
read image_hdr error=0
On first sight I would think the image file is corrupted.
Can you try the other files as well?
-
@JasonNaughton As we had another person run into a similar looking issue I had a closer look at the code and might have found why this happens. Please find all the details here: https://forums.fogproject.org/post/144691