One FOG server with multiple storage nodes?
-
Not really a problem that I can tell since (otherwise) the setup works how it’s supposed to…
So here’s the skinny - I recently rolled out a new network for a client (going from 100 Mb/s everything to 1Gb/s with a 2-4 Gb/s site/closet interlink, depending on site) and this rollout included a new ESX(i) server. The server has 4x 1Gb NICs, which are port-channeled into the switch. FOG 1.2.0 is running on Ubuntu 12.04 LTS. I set up the VM with one virtual Gb NIC; eth0.
We were doing some imaging and found out that the server saturates the 1Gb link with 3-4 clients imaging simultaneously at gig (obviously more if only at 100 Mb). So I decided I’d try to find a way to get the server to use more than one NIC at the same time so I could get more imaging throughput after verifying the host NIC was the bottleneck (rather than the server’s disk array). Originally I tried bonding four virtual NICs together and changing the storage node to use bond0, but when imaging I only saw traffic coming from one of the virtual NICs in VMware - so I ditched the idea and am trying something else. I added two more virtual NICs to the VM, eth1 and eth2, gave them their own IPs, then created two additional storage nodes pointing to the local /images directory in the FOG web config corresponding to the IP of that NIC.
When I tried pushing an image, the host got stuck at mounting image and told me it timed out while attempting to read the directory on one of the new storage nodes. I went in to the OS and disabled the other interfaces, then it successfully mounted and started imaging. As soon as I reenabled one of the other interfaces, imaging came to a screeching halt.
So here’s the big question - how do I make this work? Am I going about it in the wrong way entirely, or is there some config file that needs a few minor edits somewhere?
-
I think what you’ve tried is very close.
So, each IP address for each NIC should have a storage node defined. It’s fine to point them all to the same local directory. In such a scenario, all the nodes need to belong to the same group. For Multicasting to work (don’t know if you’re using that), one node in the group must be set as Master.
Could it be firewall?
Are there any apache error logs?
Another thing to do - and this will really help you out - is to do a debug deployment with the multiple NICs and corresponding storage nodes setup, and then to manually do the NFS mounting yourself and see how that goes, see what errors you get, and so on. We have a walk-through on this right here:
https://wiki.fogproject.org/wiki/index.php?title=Troubleshoot_NFSPlease report back with your findings, be they failure or success. Screen shots of any errors would immensely help out.
-
What mode of bonding did you setup when you did the test? Also did you make sure each virtual NIC was assigned to different physical NIC’s?
-
let me see if I understand this.
You have a ESXi server and it has 4 nic cards that are trunked to your core switch. From the core switch to the remote idf closets you have (2) 4Gb links (!!suspect!!). Your fog server has one virtual nic (eth0)
Some questions I have
- Your ether channel trunk did you use lacp on that link and is your link mode ip hash or mac hash (the esxi server and the switch need to agree on this)?
- You stated that you have 4Gb link to the idf closets? Are you using tokenring or fiber channel here?
- When you setup your fog vm, what (ESXi) style network adapter did you choose (VMXNet, or E1000)? For that OS you should be using E1000.
- What is your single client transfer rate according to partclone?
I can tell you I have a similar setup in that I have a ESXi server with 4 nics teamed with a 2 port LAG group to each idf closet. In my office I have an 8 port managed switch that I use for testing target host deployment, that is connected to the idf closet and the idf closet to the core switch.
For a single host deployment from the fog server to a Dell 990 I get about 6.1GB/min which translates to about 101MB/s (which is near the theoretical GbE speed of 125MB/s)
-
For a single host deployment from the fog server to a Dell 990 I get about 6.1GB/min which translates to about 101MB/s (which is near the theoretical GbE speed of 125MB/s)
I just wanted to point out that if you’re talking about the speed displayed by the partclone screen you’re seeing the data transferred/min after decompression, which can be faster than the raw capability of the link. This is typical speed on my network: https://www.youtube.com/watch?v=gHNPTmlrccM
-
@Junkhacker Interesting. I can say that your deployment is faster than mine. About the same image size in my environment is bout 4 min 10 sec to push out.
It would be interesting to know if your fog server is physical, what compression setting you were using, what target computer was it, and if the target had an ssd drive. (you don’t have to answer) but I’ve found that all have an impact on image deployment. But 22GB being transferred in ~2 minutes IS moving data suspiciously fast over a GbE network (I’m doubting that it could actually happen, even though I saw it with my own eyes).
-
@george1421 esxi vm, not physical. compression level 6. target is an Optiplex 3020 i5 with SSD. if only a single target is being imaged at a time, i get similar speeds almost all the time. Ethernet is near saturation, the rest is the magic of multi-threaded compression/decompression.
-
Thanks everyone for chiming in. Let me try to address everything below:
@Wayne-Workman said in One FOG server with multiple storage nodes?:
I think what you’ve tried is very close.
So, each IP address for each NIC should have a storage node defined. It’s fine to point them all to the same local directory. In such a scenario, all the nodes need to belong to the same group. For Multicasting to work (don’t know if you’re using that), one node in the group must be set as Master.
Could it be firewall?
Are there any apache error logs?
Another thing to do - and this will really help you out - is to do a debug deployment with the multiple NICs and corresponding storage nodes setup, and then to manually do the NFS mounting yourself and see how that goes, see what errors you get, and so on. We have a walk-through on this right here:
https://wiki.fogproject.org/wiki/index.php?title=Troubleshoot_NFSPlease report back with your findings, be they failure or success. Screen shots of any errors would immensely help out.
Yep, each new storage node I added I assigned the same static IP that I gave the particular interface in the OS. Only the default was set as master, and they were all part of the default group. The original IP of the server is x.x.1.20; the two storage nodes I added were 1.17 and 1.18, respectively. When I tried imaging with this configuration, it booted fine and got to the point where it had started to prep the disk to pull the image from the storage node, then just complained that accessing the 1.18 node kept timing out.
The first thing I did was disable the firewall (sudo ufw disable) but saw no change. When I disabled the other two interfaces (1.20 and 1.17) to make sure that I could at least get internet traffic on the server, it started imaging. And as soon as I reenabled one of the other interfaces, it stopped immediately.
I didn’t check any logs, though I will have a look at this again and see what I can come up with based on your suggestions.
@ITSolutions said in One FOG server with multiple storage nodes?:
What mode of bonding did you setup when you did the test? Also did you make sure each virtual NIC was assigned to different physical NIC’s?
I followed the instructions here more or less to-the-letter: https://wiki.fogproject.org/wiki/index.php/Bonding_Multiple_NICs
I used bond mode 2 and gave the bond interface the same MAC of the old eth0 NIC as reported by ifconfig. What I would have had in the interfaces file would have been similar to this:auto lo
iface lo inet loopback
auto bond0
iface bond0 inet static
bond-slaves none
bond-mode 2
bond-miimon 100
address x.x.1.20
netmask 255.255.255.0
network x.x.1.0
broadcast x.x.1.255
gateway x.x.1.1
hwaddress ether MAC:OF:ETH0
auto eth0
iface eth0 inet manual
bond-master bond0
bond-primary eth0 eth1 eth2 eth3
auto eth1
iface eth1 inet manual
bond-master bond0
bond-primary eth0 eth1 eth2 eth3
auto eth2
iface eth2 inet manual
bond-master bond0
bond-primary eth0 eth1 eth2 eth3
auto eth3
iface eth3 inet manual
bond-master bond0
bond-primary eth0 eth1 eth2 eth3@george1421 said in One FOG server with multiple storage nodes?:
let me see if I understand this.
You have a ESXi server and it has 4 nic cards that are trunked to your core switch. From the core switch to the remote idf closets you have (2) 4Gb links (!!suspect!!). Your fog server has one virtual nic (eth0)
Some questions I have
- Your ether channel trunk did you use lacp on that link and is your link mode ip hash or mac hash (the esxi server and the switch need to agree on this)?
- You stated that you have 4Gb link to the idf closets? Are you using tokenring or fiber channel here?
- When you setup your fog vm, what (ESXi) style network adapter did you choose (VMXNet, or E1000)? For that OS you should be using E1000.
- What is your single client transfer rate according to partclone?
I can tell you I have a similar setup in that I have a ESXi server with 4 nics teamed with a 2 port LAG group to each idf closet. In my office I have an 8 port managed switch that I use for testing target host deployment, that is connected to the idf closet and the idf closet to the core switch.
For a single host deployment from the fog server to a Dell 990 I get about 6.1GB/min which translates to about 101MB/s (which is near the theoretical GbE speed of 125MB/s)
The physical setup is the ESX(i) server with 4x 1Gb NICs in port-channel (not trunked, all access ports and all IPs on the VMs are on the same vlan) to a Cisco 2960x stack (feeds the labs I was working in, so no “practical” throughput limits here between switches), which has 2x 1Gb LACP links to the core switch (an old 4006). From there, there are 2x 1Gb MM fiber links to 2960X stacks in the IDFs (again, LACP); there is a 3x MM LH fiber link to a building under the parking lot (PAGP port channel due to ancient code running on the 4006 at that building). There is a remote site with a 100 Mb link through the ISP (it kills me) but FOG is not used there currently.
ESXi is using IP hash load balancing - basically identical to the config here: https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=1004048
I will double check on what NICs VMware is emulating to the OS. When I gave the VM four NICs, it was just VMNIC1, VMNIC2, etc.I usually see a transfer rate (as was noted by another poster, after decompression) of a little over 4 GB/min on older Conroe based CPU hardware (which is the bulk of what is at this site) - I can do that on up to 4 hosts simultaneously before it drops into the high 3s, at which point I can see the saturation of the NIC in the FOG console home page’s transmit graph (125 MB/s). The newest machines there I saw a transfer rate as high as 6.65 GB/min (Ivy Bridge i5s) but have yet to try sending more than one of those at a time. All the image compression settings are default.
-
@theterminator93 i just realized that you’re running FOG 1.2.0. If you’re willing to run an experimental build, you can upgrade to trunk for an increase in speed.
-
Also an option; if I upgrade and see other weird things and can’t get around the current problem, I can always just restore the entire VM to the way it was this morning.
As it turns out, VMWare is emulating VMXNET adapters. Once I finish the imaging tasks currently queued I’ll switch it over and try again.
-
Okay - this is what I get if I create a couple new storage nodes as before. This is after I switched the VMWare adapter type to E1000.
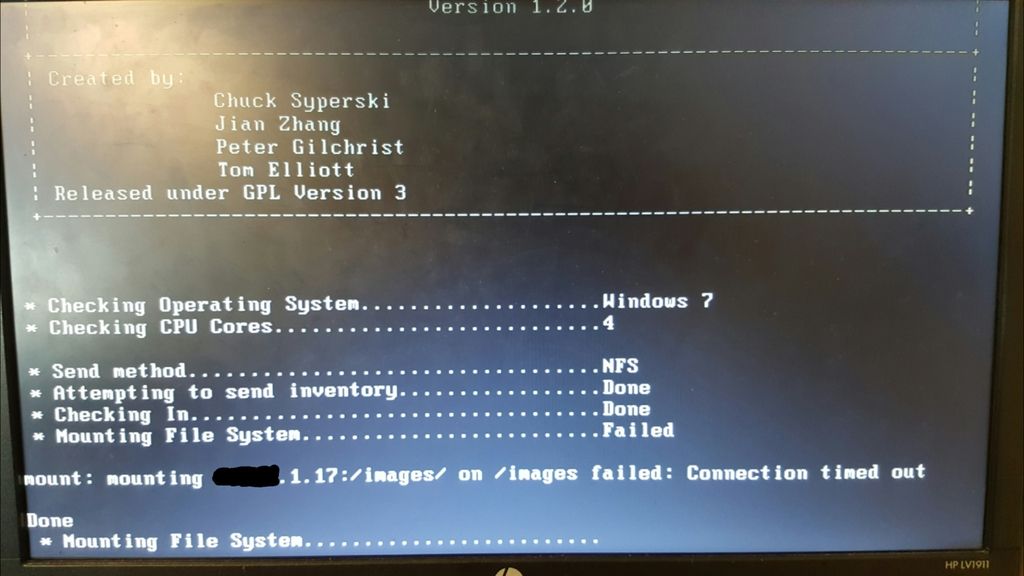
And if I disable eth0 and eth2 (the other two adapters currently enabled which have 1.20 and 1.18 addresses), it will mount and start imaging. If I start another imaging task, it will try to connect to 1.18; if I reenable that adapter, it won’t connect but the one started on 1.17 still runs. If I reenable eth0 (tied to 1.20, the master), it still runs but nothing new can connect.
Then I tried disabling the storage node tied to 1.18 and restarted the second imaging task, when connected and started imaging, though I’m not sure which node it connected to; VMware says just about all traffic to/from the server is coming off vmnic 2 and not the others.
-
@theterminator93 instead of trying to set up multiple storage nodes on the same server, have you tried nic teaming on the esxi box and using the VMXNET adapters? also, how is the speed improvement after upgrading to trunk?
-
This post is deleted! -
@Junkhacker said in One FOG server with multiple storage nodes?:
@theterminator93 instead of trying to set up multiple storage nodes on the same server, have you tried nic teaming on the esxi box and using the VMXNET adapters? also, how is the speed improvement after upgrading to trunk?
ESXi already is configured to use all four NICs an an LACP port-channel to the switch, is what you’re referring to an additional level of NIC teaming between ESXi and the guest OS? Upgrade to trunk might be a project for tomorrow (I have techs onsite imaging machines today); where is the speed improvement with that coming from - better image compression?
Is there a way to determine which storage node a particular imaging task is pulling data from? I’ve left the three adapters active in the OS and just disabled storage node 3, and imaging seems to be progressing as it should be (although only doing one at a time for the moment, so this observation is not 100% for sure yet).
-
@theterminator93 using a single VMXNET adapter on the server and the 4 nics configured that way on the esxi box should allow you to send out 4 gigabit connections at once. it won’t let 1 imaging task go 4 times as fast, but it should let 4 tasks go at once without slowing down because of network connections (though your other hardware may not be able to keep up). this is all theory to me, since i haven’t tried it though. the speed improvement on imaging with trunk mainly comes from a change in the decompression method. the image must be decompressed before it is piped to partclone. fog 1.2.0 used a single processing thread, trunk uses multiple. see the video i posted for an example of the current speed we get.
-
@theterminator93 There was also an issue with vmxnet depending on what version of ESXi you are running on. Where it would slow down under heavy load. The recommended fix was to use the e1000 network adapter.
I guess I have to ask the question at what level do you need to image your machines? With 4-6 minutes per image download you can chain load images and start a new system deploying every 6 minutes giving you 10 per hour? Maybe unicast imaging is not the right solution for you. If you need to image 10s of systems per hour you may want to look into multicasting (which brings its own problems too?).
So to ask the question that should have been asked earlier, how many machines do you need to image per hour?
-
It’s an ESXi 6.0 host. I did notice that with the VMXNET adapter as the emulated NIC that the OS was seeing a 10Gb link speed… however that was the config under which I was seeing Ethernet throughput choke with more than 3 clients unicasting.
Funnily enough I had tried multicasting a lab first, which… didn’t work (the infamous problem where all hosts check in but don’t start deploying). I really should look into that as well since, truth be told, it’s definitely the way to go when pushing the same image out to identical hardware. My motivation for pushing the limit of how many unicast tasks I can run simultaneously is because this client has an extensive (not in the good way) assortment of hardware and applications out there, varying from single threaded Northwood P4s up to Broadwell i5s (guess which they have more of…).
I’m definitely going to try out trunk to see how it runs with multithreaded decompression. I’ve also read of a number of other items that have been addressed which I’ve not really run into issues with so far, but it’d be reassuring to know there’s less of a chance of them dropping in on me unexpectedly.
Regarding the number of machines that “need” to be imaged per hour… first and foremost the setup I had before trying to push the envelope with this endeavor was already a tenfold improvement over the old setup; a 100 Mb server, 100 Mb switches, etc. So just with the new infrastructure we’ve gone from 30 minutes per machine to less than 10. My vision is where one person can go into a classroom to boot up a host, register it (if needed) and start the imaging task, then and walk away then go do the next machine in the next room and have none of the machines need to wait in the queue to start pulling an image - while all image at peak throughput relative to the capability of their hardware. In short it’s the “new network… push it to its limits to see what it’s capable of” mindset.
Upon leaving for the afternoon I had disabled storage node 3, but storage node 2 as well as the default remained enabled and imaging tasks seemed to proceed normally. I still haven’t confirmed whether or not it’s using two NICs to handle throughput yet though - but hopefully I’ll have an opportunity to examine that tomorrow.
Thanks everyone for the input and suggestions. The fresh perspective helps keep me from digging too deep in the wrong places.
-
Minor update.
I haven’t changed anything today yet but did image a lab this morning. While the lab was going I didn’t see a single occurrence of a machine getting the error I had before (unable to mount) with two storage nodes active. I had no discernible slowdowns while imaging one machine at gig while simultaneously imaging 7 others at 100 Mb (old 2950 switches still in this building). I was also seeing traffic coming off of more than one vNIC according to VMWare.
Until I try and do 4-6 or more simultaneous imaging tasks at Gig on the new network I won’t know for sure if the > 1000 Mb/s throughput “barrier” is broken.
I’ve got one last model’s image I’m uploading today, then I’ll do the trunk upgrade and do some more tests to see how things look.