Removing MACs from multicast task without starting over
-
I’ve had it happen a couple of times this week where I’ve started a FOG multicast task with up to 50 machines and then I won’t be able to get one or two machines to boot into FOG (or, as happened earlier, one machine started writing the image early for some unknown reason) and then I’ve been forced to stop all of the tasks and start over, rebooting all of the machines etc because FOG is waiting on one or two last machines to appear before it will start the multicast.
I have tried to cancel/remove individual machines from a multicast task but it seems to stop/remove all of the existing tasks. Is there a way to fix this situation and to get FOG to start a multicast task without cancelling all of the tasks and starting over?
I also seem to be having an issue with machines not changing their hostname to match what they’re known as to the FOG server. We’re using Windows 10 on the clients. I’ve installed the FOG client, set the address of the FOG server for the client and it has worked for most of the machines but not all. They’re all on the same network / switch but there are two types of PC with different network adapters if that could make a difference?
-
@danboid For the renaming problem, we need to see a fog client log file. Should be on the root of the C drive. Please include enough of the file, a single line usually is not helpful.
-
@danboid said in Removing MACs from multicast task without starting over:
I have tried to cancel/remove individual machines from a multicast task but it seems to stop/remove all of the existing tasks. Is there a way to fix this situation and to get FOG to start a multicast task without cancelling all of the tasks and starting over?
Not that I know of with FOG as it is right now. Not saying this can’t be changed though. If you are keen you can start looking into this part of FOG and try to work out how to do what you want it to.
-
I woke up thinking about this today and I know one potential way we could mostly fix this problem.
If a big FOG multicast task fails then, unless the user has AMT or whatever the AMD equivalent of that might be, they have to manually turn off many computers before they can start the next FOG task. Therefore it would be handy if there was a way to shutdown FOG clients that have booted and started partclone so that they can be remotely powered down by just ticking a checkbox next to that machine in the FOG web UI’s task list then choosing a ‘Shutdown selected hosts’ option.
This feature would ideally work with Intel, AMD and ARM based clients so it wouldn’t rely upon Intel-specific AMT for example. It would use a FOG client service to perform the shutdown. It’s not quite a full fix for my original stated problem but it would mostly heal the pain of dealing with large failed FOG multicast tasks in a way that fits the current workflow. Does this sound viable?
-
@danboid FOG multicasking uses udp-sender and udp-receiver to move the image stream between the FOG server (master node) and the target computers.
The udp-sender has some parameters that can be used like
–min-receivers
–max-wait
These values should be present in the FOG ui. You would set the min number of receivers before the stream starts. Once all of the receivers have connected then imaging should start.
The max wait value says that if all of the receivers haven’t joined by this time, the stream will go ahead and send anyway. That should be the way it works. If a target system is late to the party it will just miss the stream and have to sit an wait until the next one, but since you can not use the same stream name over again, it will wait forever.ref: https://linux.die.net/man/1/udp-sender
On the client side the udp-receiver is used. Again there are two value of interest that should be used (I can’t say for certain because I haven’t looked at the FOS Linux code yet to confirm)
–start-timeout
–receive-timeout
The start timeout should abort udp-receiver if it hasn’t received a data stream in xx seconds. This could be set to something like 300 seconds (5 min) or longer if needed. The receive timeout would be used if the stream started, but then stopped for some reason before the actual transfer is complete (i.e. someone aborted the udp-sender mid stream). Hopefully udp-receiver would set an error level so it could be trapped by the script that it was aborted. From there if either of the two conditions happened the FOS Linux engine would just issue a reboot command.ref: https://linux.die.net/man/1/udp-receiver
This feature would ideally work with Intel, AMD and ARM based clients so it wouldn’t rely upon Intel-specific AMT for example. It would use a FOG client service to perform the shutdown. It’s not quite a full fix for my original stated problem but it would mostly heal the pain of dealing with large failed FOG multicast tasks in a way that fits the current workflow.
The OS that runs on the target computer is linux based. It is a customized version of linux but it has the ability to issue a reboot command to restart the OS, or maybe better to just power off the target computer since it already missed the stream start. The hard part would be for the FOG server to find the target computer. If it could then it could send a restart command to the target computer. I think its better for the client to be self healing in that a watchdog or timeout of the udp-receiver would be better.
One last bit, the FOG client is not running at this point in the imaging process, so its just the fog server and fos linux systems that are the actors here. The FOG Client only runs in the target OS.
-
It looks like the code that runs on FOS Linux doesn’t use these timeout values.
It looks like its possible to add them with little effort. The next step would be to see if we can trap the timeout so the code could issue a power off command.
Edit: With some crude testing it appears that udp-receive will exit with exit code 0 on a successful reception and 255 on a receive timeout (–start-timeout) so we can trap when it unsuccessfully starts the stream.
-
Yes, being able to start multicast tasks with a timeout would do the trick. I’m surprised FOGs lack of support for a receive timeout hasn’t been raised until now.
-
@danboid said in Removing MACs from multicast task without starting over:
I’m surprised FOGs lack of support for a receive timeout hasn’t been raised until now.
Probably because no one has run into the issue or just worked around the issue. The other thing is multicast imaging is temperamental on the setup and really network dependent. If folks can’t get it working easily they just give up and use unicast imaging 10 computers at a time. I think we can make this work like you need without much refactoring.
So based on your experience and deployment size, how long does it take to get a multicast deployment setup and imaging to start? What I’m looking for is the initial timeout from the time the computers are told to boot until the stream should start. Would that be 5 minutes or something longer? I think powering off is the right answer instead of rebooting. You can always wake them up using WoL if you need to after the fact. Thinking about it, it would be a nice to have if the computers could indicate that they didn’t receive the stream in time and powered off instead of imaging. We could probably do that with an out of band (outside) of fog curl call to the FOG server with a specific php page to send out the email. But that will take a bit more refactoring than just adding a timeout value.
-
Hi George
I would say 20 minutes / 1200 seconds would make a good default timeout, if you have a lab of 50 machines that don’t support WoL and you have to manually PXE boot every one and enter a BIOS password to use the boot menu. Notice I say default because I’d prefer that the timeout was configurable when you create the multicast task.
As you say, it would be best if those machines that don’t make the timeout would shut themselves down rather than reboot because this works out for the best if you are using WoL.
Do you want me to open a github ticket for this?
-
Thinking about it, if you’re manually booting 50/60 machines all with passwords, I think 20 minutes is cutting it a bit fine. 30 minutes seems much more doable for that size of task so I think I’d prefer to use a 1800 second timeout as default.
-
I have created a gh ticket for this feature request:
-
@danboid said in Removing MACs from multicast task without starting over:
Do you want me to open a github ticket for this?
Well we need to look at what can be done today and what can be done in the future. So the quick answer is what we can do today to make things a bit easier for you right away.
As for the server wait before imaging that is a global setting in the FOG Configuration -> FOG Settings page.
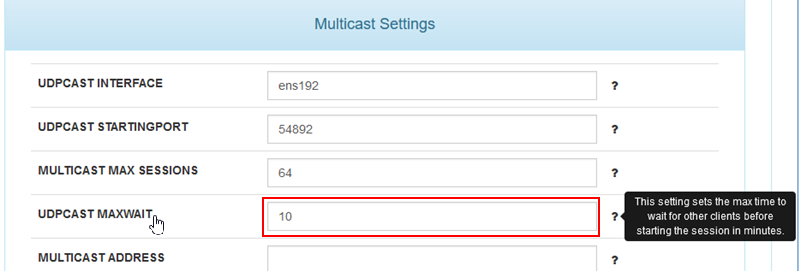
The number of multicast clients are defined when you create the multicast task.
On the other site, for those clients that don’t make it in time for the stream I can create a one-off virtual hard drive where we can hard code a shutdown timeout and/or pass a parameter from the FOG server to set the timeout. The parameter passed from the fog server will still be static, but could be adjusted globally from the fog server. What would be missing is an admin editable field in the web ui. I’ll need to think about that for a bit. But it should be possible.
-
On the client side the udp-receiver is used. Again there are two value of interest that should be used (I can’t say for certain because I haven’t looked at the FOS Linux code yet to confirm)
–start-timeout
–receive-timeoutYeah that might be a good option to make clients shutdown after a certain amount of time. I’d suggest we use the same value we have in the web UI already (UDPCAST MAXWAIT) and shutdown clients after that time.
With some crude testing it appears that udp-receive will exit with exit code 0 on a successful reception and 255 on a receive timeout (–start-timeout) so we can trap when it unsuccessfully starts the stream.
Sounds reasonable.
I won’t talk much about udp-sender (FOG server side) as I think
--min-receiversand--max-waitare already in use and adjustable as much as it makes sense. Receivers count is set to the amount of clients you have in your group (if done as a group deploy) and I don’t see a point in doing this any other way. This is one of two start signals: a) all clients are connected or b) max-wait time is over.Web GUI issue? Please check apache error (debian/ubuntu: /var/log/apache2/error.log, centos/fedora/rhel: /var/log/httpd/error_log) and php-fpm log (/var/log/php*-fpm.log)
Please support FOG if you like it: https://wiki.fogproject.org/wiki/index.php/Support_FOG
-
@sebastian-roth said in Removing MACs from multicast task without starting over:
I’d suggest we use the same value we have in the web UI already (UDPCAST MAXWAIT) and shutdown clients after that time.
I can see that, but the doubt I have is that I don’t think that value is passed onto FOS Linux since that (currently) is a server side parameter.
I won’t talk much about udp-sender (FOG server side) as I think --min-receivers and --max-wait are already in use and adjustable
Yes I’m not seeing any value in changing the server side because that is well established and working well. The only “nice to have” would be on the client side if they don’t get on the stream in time they will just sit and wait forever. It does sound like the OPs setup is a bit more complex since it requires an Imaging admin to enter a bios password to boot them into imaging. But that is a bit out of scope on this issue.
-
@george1421 said in Removing MACs from multicast task without starting over:
I can see that, but the doubt I have is that I don’t think that value is passed onto FOS Linux since that (currently) is a server side parameter.
Absolutely right. That would be a next step to improve the way machines act when booted into a multicast task but can’t pick it up - either because the whole session times out on the server side or because a particular client is too late to join.
Anyone keen to draft the changes involved to get this to work?
@danboid You might want to update the github issue report to reflect things discussed here.
Web GUI issue? Please check apache error (debian/ubuntu: /var/log/apache2/error.log, centos/fedora/rhel: /var/log/httpd/error_log) and php-fpm log (/var/log/php*-fpm.log)
Please support FOG if you like it: https://wiki.fogproject.org/wiki/index.php/Support_FOG
-
@sebastian-roth said in Removing MACs from multicast task without starting over:
Anyone keen to draft the changes involved to get this to work?
I’ll take a look at the FOS Linux side tonight. I have the build environment still setup at home when i was failing at integrating partclone 0.3.20 into the image.
For the kernel parameter to FOS, should we use
MCASTMAXWAITas the variable? If its not set then set the default timeout to 15 minutes? -
@george1421 said in Removing MACs from multicast task without starting over:
For the kernel parameter to FOS, should we use
MCASTMAXWAITas the variable? If its not set then set the default timeout to 15 minutes?I had a quick look at the kernel parameters used so far. Looks like they are mostly in camel case, so you might spell it as
mcastMaxWait.I am not sure about the default yet. People are used to the behavior of clients waiting forever. While I do see this as a huge improvement to shut those down instead I am still wondering if changing the default could cause consequences in some circumstances?
And if we add the default I wonder if 10 minutes is better just so it’s the same default we use for
--max-waiton the server side. But I am fine with 15 minutes too.Web GUI issue? Please check apache error (debian/ubuntu: /var/log/apache2/error.log, centos/fedora/rhel: /var/log/httpd/error_log) and php-fpm log (/var/log/php*-fpm.log)
Please support FOG if you like it: https://wiki.fogproject.org/wiki/index.php/Support_FOG
-
@sebastian-roth said in Removing MACs from multicast task without starting over:
And if we add the default I wonder if 10 minutes is better just so it’s the same default we use for --max-wait on the server side.
Ideally we would want the fog php code to manage this kernel parameter, but in the case the parameter isn’t set then give it this value is what I was thinking. The actual fix will require 2 parts. 1) in FOS coding (what I will work on) and 2) In the php code to add the parameter to the settings and then have the php code pass that kernel parameter on the multicast startup. That part is above my skill set it seams.
-
Oh so you can already configure the udpcast max wait in the current stable release? That’s good news. I have closed my github ticket because it focused on adding the max wait timeout. I’m happy enough with it being a global setting, I don’t need to change it per task.
I didn’t know to look for this setting until raising this problem here. I have mostly stuck to FOGs presets every time I’ve used it up until now, I just up the max number of clients, update the FOG kernel and tweak the DHCP config if required.
There doesn’t seem to be a guide to setting up multicast tasks in the official docs? Am I missing it? If there is such a guide it should mention adjusting this setting to suit your situation first.
-
@george1421 said in Removing MACs from multicast task without starting over:
In the php code to add the parameter to the settings and then have the php code pass that kernel parameter on the multicast startup. That part is above my skill set it seams.
I will look into that. Though as I said I will use the parameter we already have and pass it to the kernel instead of adding a new setting parameter.
Thanks you for checking out the FOS part.