Edit: So, the target PC was not identical after all. It had an optical drive as well. Don’t know why that would change anything. From dracut emergency shell I found that the driver for the SAS controller card (aacraid) was not loaded for some reason. Works fine on other target PCs without the optical drive…
T
Posts
-
RE: RHEL 8.10 clones fail to bootposted in Linux Problems
-
503 Service Unavailable When Remote Storage Node is Off-lineposted in FOG Problems
Hi all,
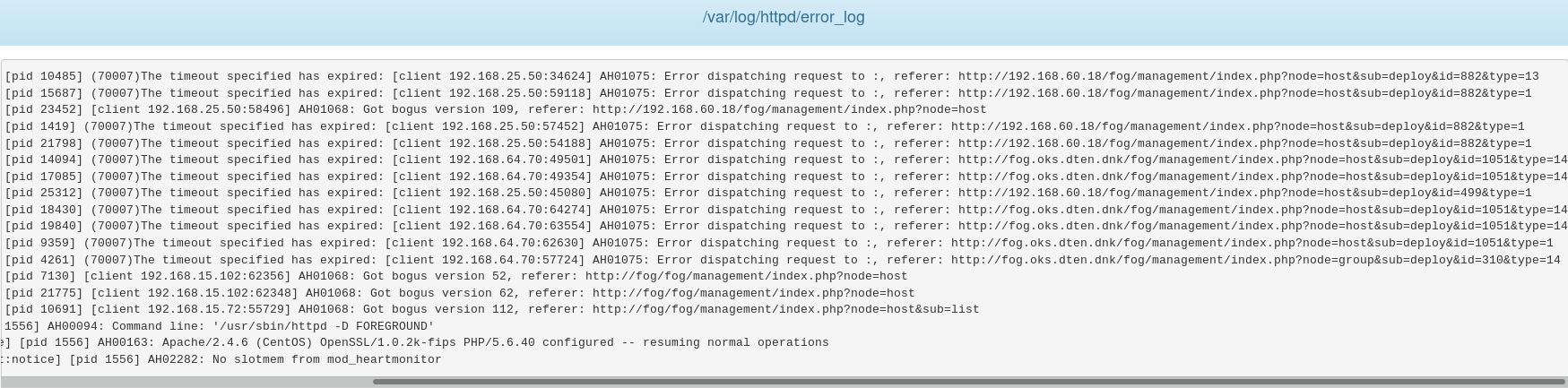
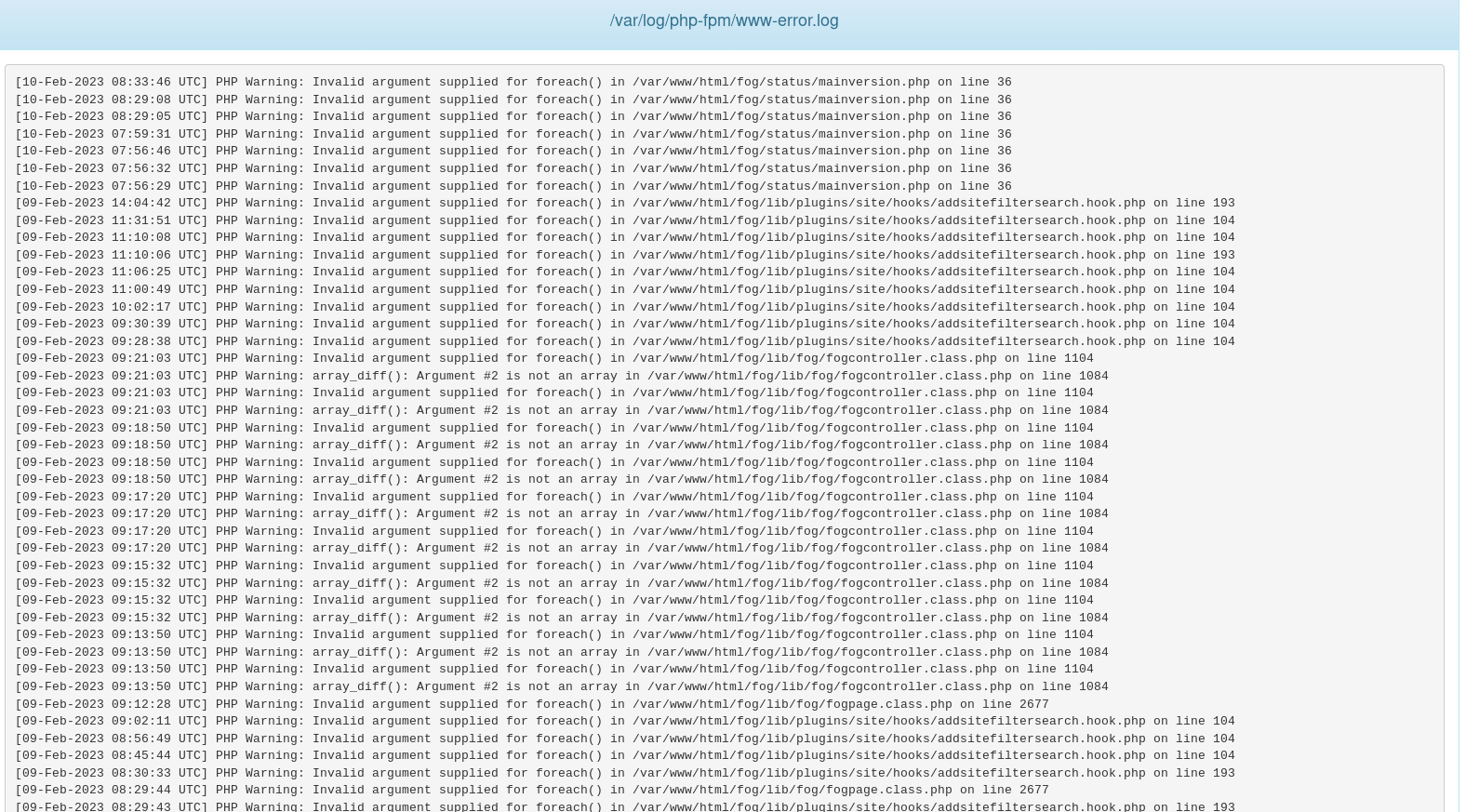
We have a distributed setup with a master server at our central site and storage nodes (each is a master node in separate storage groups/sites/locations) at remote sites. This setup works fine. However, if we lose connectivity to a storage node or shut it down intentionally, the Fog WebUI starts timing out when tasking with WoL checked. Tasks are still completed - it’s just the tasking confirmation that times out.
It seems the master server is expecting some reply from all nodes when tasking - even if the tasked host isn’t associated with the site and location that the off-line node resides in. This may be per design that it will try and wake hosts up even if they have moved from one site to another without the site and location associations updated? Or is it the site and location plug-ins that are not fully hooking in to FOG?
Apache error log from master server:
PHP-FPM error log from master server:
Master server and nodes:
CentOS 7.9
FOG v1.5.9Not a major issue but I’ve not seen any posts relating to this in particular.
Thanks.
-
RE: Storage Node Kernelsposted in FOG Problems
@Sebastian-Roth said in Storage Node Kernels:
Yes, that’s another way to do it.
Actually, for us it is necessary (even for the master node) as we’re are isolated from the internet. That means the installer will fail to download inits and kernels.
-
RE: Storage Node Kernelsposted in FOG Problems
@h4x0r101376
Yeah, I’ve noticed this as well. Even if setting the checkmark for the location (when using the Location plug-in) to use local inits and kernels, it is not replicating them. I’ve simply copied them from the master node to the node webfolder. -
RE: Setting up FOG in multi-location environmentposted in FOG Problems
@Sebastian-Roth Sure, happy to help in any way I can…
-
RE: Setting up FOG in multi-location environmentposted in FOG Problems
Thanks for replying.
First of all - we have it working now.
Regarding multicasting the node logs showed an error about the interface not being ready for some reason. The age old secret and very esoteric IT-tech hack known as “server reboot” fixed that issue. I don’t know what the issue was as such as server access, unicasting, deploying snap-ins, dhcpd (everything else, really) all worked fine. I guess we should end the process of changing from standard install to FOG node with a reboot from now on.
As for WoL we wiresharked the VLANS and found that the node DID in fact send magic packets for hosts on remote VLANS. It turned out that IOS-XE v17 is buggy and needs an extra setting on the ingress interface, i.e. the interface on which the server or node sends the magic packets. You need to set “ip network broadcast” as well as the usual “ip directed broadcast <ACL#>”. We have identical routers at all sites (Cisco 1111-4P), but some are from a previous purchase an thus has IOS-XE v16. Here WoL works when setup as described here:
https://wiki.fogproject.org/wiki/index.php/WOL_Forwarding
So maybe an addition to the wiki would be helpful to others doing WoL forwarding.Anyway, thanks for taking your time to confirm we were doing it the right way.
-
Setting up FOG in multi-location environmentposted in FOG Problems
Hi,
We’re trying to change our setup from just a bunch of unrelated FOG servers on multiple sites to a setup that automatically replicates images and snap-ins from the central site to satellite sites.
To accomplish this we have installed the Location (and Site + Access Controls to limit what’s visible to satellite fog users) Plug-in, installed all satellite site FOG servers as Storage Nodes to the central site Master Node and attached each node to a separate location.
At the central site we have a score of VLANS, all hosts are on different VLANS from the Master Node. At satellite sites we have hosts on two VLANS, where one is the same as the storage node VLAN. Routing is setup and allows multicasting, ip pim is set on the VLANs the server is not on.
Directed broadcast ACL permitting the local storage node for WoL is set for all routed VLANs at all sites.
Hosts are attached to locations and sites corresponding to their physical locations.
Replication is working fine. However, multicasting is not working at satellite sites. Clients just hang at the blue imaging screen after receiving the task. Unicasting is working.
WoL is not working at satellite sites VLANs different from the the Storage Node VLAN. Wireshark shows that no magic packets are sent to the routed VLAN, only on the same VLAN as the Storage Node, even though it is defined in the WoL Broadcasts menu. It is as if the Location Plug-in is not reaching in to the WoL Broadcast menu for the satellite node to be able to send magic packets to the correct VLAN?
Both multicasting and WoL worked with current network settings before changing from full FOG servers to Storage Nodes.
To try and get multicating to work at satellite sites, we tried adding separate Storage Groups and assigning each satellite node to their own Storage Group, setting each node as Master Node for their corresponding group, adding the Storage Groups to the images and snap-ins as described in this post:
https://forums.fogproject.org/topic/11653/multi-cast-with-location-plugin-enabled/18?_=1673903176664
That didn’t do the trick, though.Is it even possible to do it this way? I suppose we could fix both issues by making the satellite nodes fully fledged FOG servers with different Storage Groups and then assigning multiple Storage Groups to images and snap-ins?
That would leave us with a separate DB and user administration at each site, though.
We’re running FOG 1.5.9 on CentOS 7.9 at all sites. Central site is a physical server, satellites sites are virtual servers on ESXi 7.
Any help appreciated - Thanks.
-
RE: Dual NIC clientsposted in Linux Problems
That would work nicely, seeing you can use different inits. I didn’t know that as it is not possible in 1.2.0.
The caveat is that I would have to redo the server as trunk requires a newer Ubuntu according to @Quazz.
-
RE: Dual NIC clientsposted in Linux Problems
@Wayne-Workman
Thanks again.Yes, that code will only work on the specific network defined in $nwid and if the kernel names the interfaces ethX and probably only if the number of interfaces match that particular piece of hw…
Mighty nice of you to help me out here… Appreciate it.
Thanks.
-
RE: Dual NIC clientsposted in Linux Problems
Thanks for the reply.
Seems kind of inflexible, though… The same init is used for all, right? We even have some clients with three NICs at other locations… If it has to take various hw scenarios into account, it might take some fancy scripting.
I know some basic scripting but nothing really fancy.
The only way to determine the correct interface would be to filter on IP, as I see it.
So maybe a list of interfaces and then for each ethX in the list:
#!/bin/csh set nwid = X.X.X set list = (eth0 eth1) foreach eth ($list) set ip = `ifconfig $eth | grep inet | awk '{print $2}' | sed 's/addr://' | cut -c-10 ` if ($ip == $nwid) then ifup $eth else ifdown $eth endif endThat would in my case get the network ID of the correct network and other disimilar outputs from the other interfaces in the list which could then be compared to a set value of the correct network ID. Based on that comparison you could then turn on or off the interfaces.
I’m sure someone else could do something a lot niftier.
I haven’t tested any of this and it might screw up if the number of interfaces actually present is different from the number in the list.
-
RE: Dual NIC clientsposted in Linux Problems
@Quazz and @Wayne-Workman
Thanks for the suggestions.
I tried playing around with grcan.enable0=[0|1] and grcan.enable1=[0|1] as well as grcan.select=[0|1] but none had any effect. The kernel continues to choose the slower link in most cases. Seemed promising, though…
What I do notice for the first time, though, is that whatever NIC is not chosen is disabled. I hadn’t noticed as I can’t see the backs of the boxes very well. Here it is also obvious that the active NIC changes on occasion, as the LEDs die on the disabled NIC.
-
RE: Dual NIC clientsposted in Linux Problems
@Quazz
No, they are registered and deployed through tasks. Actually it’s not a question of one NIC being faster than the other - they’re more or less identical mobo dual NICs - as it is the link speed. They’re 100Mbps switch ports on a 100Mbps trunk to the layer 3 switch. It was never intended for large data transfers - just remote access and so on.The primary MAC in the host registration is the faster link, so that has no effect, I’m afraid. These are 1Gbps switch ports for the clients and two ports in ether channel for the server.
-
RE: Dual NIC clientsposted in Linux Problems
@Quazz
Yes, sometimes an image will deploy at 5GB/min - a few minutes later when trying again with the same client it will only deploy at a fraction of that speed…Otherwise I agree; I too believe it has to do with the order of the NICs.
I tried swapping the cables at first to see if it just chose one specific hardware ID first, but that was not the case.
Since then I’ve done quite a few test deployments on the same eigth machines. Mostly they’ll deploy slowly, but every now and again one will run on the faster NIC, which can be verified by pulling the cables and seeing which one makes it pause.
I’m not saying it’s arbitrary, but I don’t see a pattern so it seems arbitrary to me.
")
-
RE: Dual NIC clientsposted in Linux Problems
OK - did some thinking. It times out because there is no default gateway set on the secondary link. Setting that it will connect. The problem is, how do I know which network it chooses? I’m getting inconsistent transfer speeds now, average of 5GB/min versus 225MB/min - apparently depending on which NIC it connects through.
I should mention that inter-VLAN routing is enabled on the layer 3 switch of the primary network. Removing the secondary network from the static route list or pulling the physical link kills it again - this time at trying to send an inventory before deploying.
If I pull the power on the secondary network they will all deploy at high speeds.
With the secondary network on (and inter-VLAN routing), some will deploy normally, others slowly - apparently arbitrarily, as the same machines will act differently from task to task.
It would seem the kernel arbitrarily sets which NIC is eth0 from boot to boot? That would perhaps explain why it would appear to use different NICs.If I pull the plug on the secondary network while deploying it stops deploying until plugged back in. So it’s using the “wrong” NIC…
Anyone ever see something like this?
-
RE: Dual NIC clientsposted in Linux Problems
@Quazz said in Dual NIC clients:
Sorry, it’s still morning, things got mixed up in my head.
LOL, tank up on your morning stimulant of choice…
-
RE: Dual NIC clientsposted in Linux Problems
@Quazz - Thanks again.
How do you mean define which NIC to use in FOG? I see only options for setting the server side NIC… Am I missing something here?
-
RE: Dual NIC clientsposted in Linux Problems
@Quazz - Thanks for the reply.
You’d be correct in assuming that next-server is set as per default by the FOG installation script.
If i understand you correctly, your suggestion of trunking would enable the client to connect to the TFTP server on either link? I’d rather not, as the other link is only 100Mbps on some cheap Cisco 2960 SI series.
Ideally the clients would choose the correct link matching the network ID of the next-server.
-
Dual NIC clientsposted in Linux Problems
Hi,
We use dual NIC client boxes, each on different VLANS. Machines will PXE boot but the screens go blank during that process. In earlier versions (0.28, 0.29 and 0.32) we’d get a TFTP time out.
The quick and dirty fix is to kill the relevant switch ports on the LAN not used for FOG while imaging.
Since it works fine with only one active NIC, it would seem that the pxe booted kernel gets confused about which interface to use for TFPT. I tried changing TFTP_ADDRESS=“0.0.0.0:69”; in /etc/default/tftpd-hpa to point at the server IP, but that didn’t help. I also tried adding option tftp-server-name X.X.X.X; to my dhcpd config file, but no luck.
Any ideas?
Thanks.
Server:
FOG 1.2 (pretty much standard setup except for bonded NICs)
Ubuntu 10.04.4 LTSClients:
HP z620
Lenovo ThinkStation S10