Centos 7 UUID not updated during imaging - will not boot
-
SERVER
FOG Version: 1.5.9
OS: centos 7.9CLIENT
OS: centos 7.9DESCRIPTION
When we image our centos 7.9 system, which is using UEFI boot and UUID in /etc/sftab, the pc being imaged shows a kernel panic and displays that the UUID for “/dev/disk/by-uuid/(uuid here) does not exist”. Does FOG not change the UUID to match the new system when it finishes imaging? I found an article from 2017 that shows this issue was fixed for a swap UUID. -
@Gerrit-Anderson The FOS inits do read the UUID from the source partition table and apply those to the destination system.
Please post the contents of the text file
d1.partitionsfor this particular image. You find that on your FOG server in/images/#IMAGENAME#/d1.partitions -
@sebastian-roth Thank you for the reply. I have the contents of the d1.partitions file below.
label: gpt label-id: 3F338E38-6A09-4FCE-92B1-B465C0ED8E35 device: /dev/sda unit: sectors first-lba: 34 last-lba: 209715166 sector-size: 512 /dev/sda1 : start= 2048, size= 409600, type=C12A7328-F81F-11D2-BA4B-00A0C93EC93B, uuid=3DD480BD-6B22-4812-B5E1-2310A243D7F2, name="EFI System Partition" /dev/sda2 : start= 411648, size= 2097152, type=EBD0A0A2-B9E5-4433-87C0-68B6B72699C7, uuid=D8C4A9F7-60A1-4B79-874D-55BE7824CE32 /dev/sda3 : start= 2508800, size= 62914560, type=EBD0A0A2-B9E5-4433-87C0-68B6B72699C7, uuid=68E3E8A9-3938-4489-9A05-B2257D5934C6 /dev/sda4 : start= 65423360, size= 16517120, type=0657FD6D-A4AB-43C4-84E5-0933C84B4F4F, uuid=36DB8CD8-56C2-4CEF-8652-3640AE9E19AF /dev/sda5 : start= 81940480, size= 127772672, type=EBD0A0A2-B9E5-4433-87C0-68B6B72699C7, uuid=F056C997-2D96-4DDF-98D3-5E4BD44C1378None of the UUID’s listed in this file match the UUID’s of the original image master. I can confirm that once the client gets imaged, it starts to boot CentOS and then goes to the emergency shell stating “/dev/disk/by-uuid/ (uuid here) does not exist” The UUID it shows matches the UUID from /sda5 on my master.
Any help is appreciated!
-
@sebastian-roth Update - This master image was created on a Gen 2 HyperV VM. Not sure if that could be causing an issue…? Seems like if I send the image to any of my HyperV hosts, it works perfect. UUID’s are exactly the same as the master, image boots and operates normally. When I send the image to a desktop is the only time I have this issue.
-
@Gerrit-Anderson Can you please run
sfdisk -d /dev/sdaon the master and post output here? -
@sebastian-roth The output from sfdisk -d /dev/sda is below:
# partition table of /dev/sda unit: sectors /dev/sda1 : start= 1, size=209715199, Id=ee /dev/sda2 : start= 0, size= 0, Id= 0 /dev/sda3 : start= 0, size= 0, Id= 0 /dev/sda4 : start= 0, size= 0, Id= 0 -
@sebastian-roth To add more troubleshooting steps:
Master Image created on HyperV as a Gen 2 (UEFI) VM:
HyperV to HyperV works fine, even to different hosts
HyperV to AMD PC (UEFI) doesn’t boot, missing disk message
HyperV to Intel PC (UEFI) doesn’t boot, missing disk messageMaster Image created on AMD PC (UEFI):
AMD PC to AMD PC works fine
AMD PC to Intel PC (UEFI) works fine
AMD PC to HyperV doesn’t boot, missing disk messageIt seems to be an issue with the virtual machine from what I can tell… For the time being, I will keep two images, one for VM’s and one for physical machines… I would like to have an end result of one image working on HyperV and Intel/AMD based desktops. If you have any other troubleshooting steps I can try, I am willing to give them a shot.
I appreciate the help so far!
-
@gerrit-anderson said in Centos 7 UUID not updated during imaging - will not boot:
/dev/sda1 : start= 1, size=209715199, Id=ee
Looks like the CentOS 7
sfdiskcommand is not able to read GPT partition layout. This is just the protective MBR entry.Can you please schedule a debug capture task for the master, boot it up and when you get to the shell run
sfdisk -d /dev/sdaagain. Take a picture and post here. -
@sebastian-roth So it looks like sfdisk may not support gpt? I ran a couple more commands, not sure if this shows exactly what you are looking for… These were ran in the debug shell.
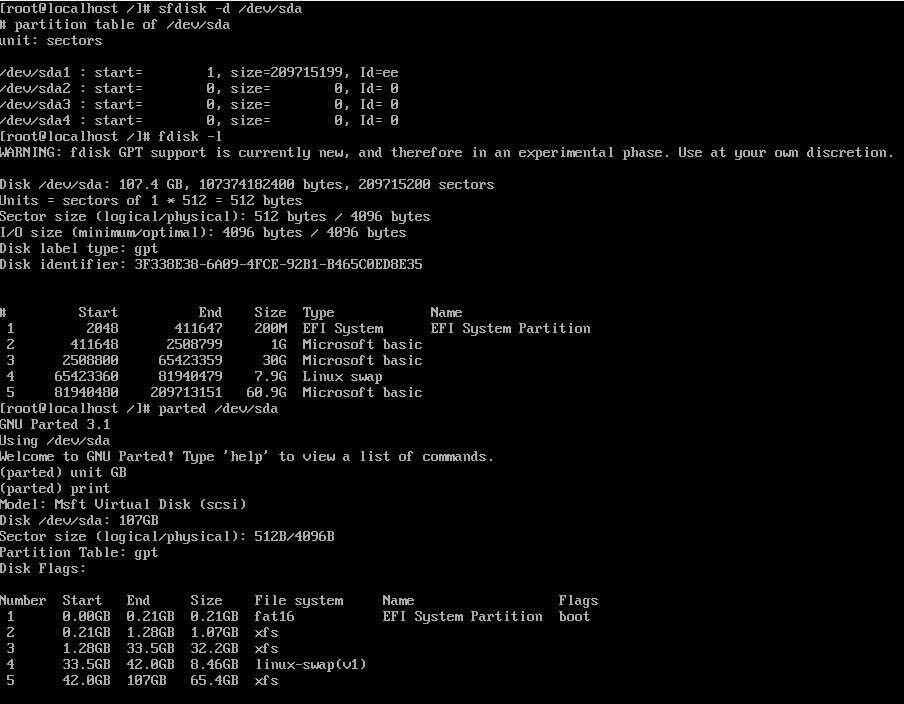
-
@gerrit-anderson said in Centos 7 UUID not updated during imaging - will not boot:
These were ran in the debug shell.
Can’t get my head around this. You say your FOG server is 1.5.9. Do you use a custom FOS init?
Please run
sfdisk --versionin the debug shell and post version here. -
@sebastian-roth The sfdisk version is
sfdisk from util-linux 2.23.2Yes, FOG 1.5.9 most recent download, CentOS 7.9 (latest version 7)
-
@gerrit-anderson said in Centos 7 UUID not updated during imaging - will not boot:
The sfdisk version is
sfdisk from util-linux 2.23.2Hmm, this version is really old. We are at 2.35.1 at the moment and 2.23.x was used in buildroot back in 2013. I don’t think we had our FOS image build with such an old version at any point really. For GPT support you need 2.26.x at least I read in the man page. I have no idea how you can have a FOS init with this old versioned sfdisk command.
I suggest you download the latest inits from our server and try with those:
sudo -i cd /var/www/fog/service/ipxe/ mv init.xz init.xz.old mv init_32.xz init_32.xz.old wget https://fogproject.org/inits/init.xz wget https://fogproject.org/inits/init_32.xz chown fogproject:apache init* -
@Gerrit-Anderson Just checked on the official FOS init used with FOG 1.5.9. Version of sfdisk/util-linux is 2.35.1. No idea where you got yours from.
Sure you run this in the FOG debug command shell? Scheduling a debug capture task and PXE boot the machine into it?!
-
@sebastian-roth I may not be understanding this fully, but I ran this command on my master image. That shouldn’t have any impact on anything related to FOG right? The sfdisk that I am using must be what ships with CentOS 7… I also ran this command on my FOG server, and its the same version, but that is also running CentOS 7.
-
@sebastian-roth Ahhh, no. I will do that now. I did not do this in the FOG debug shell. This was all done within CentOS. I apologize… Doing this now!
-
@gerrit-anderson said in Centos 7 UUID not updated during imaging - will not boot:
The sfdisk that I am using must be what ships with CentOS 7… I also ran this command on my FOG server, and its the same version, but that is also running CentOS 7.
Ahhh, now we are talking!! What I am asking you to do is, schedule a debug capture task and PXE boot the machine into it. Then you get to a command shell and run the
sfdisk -d /dev/sdacommand there. -
@sebastian-roth sfdisk version is 2.35.1 Below is output of sfdisk -d /dev/sda
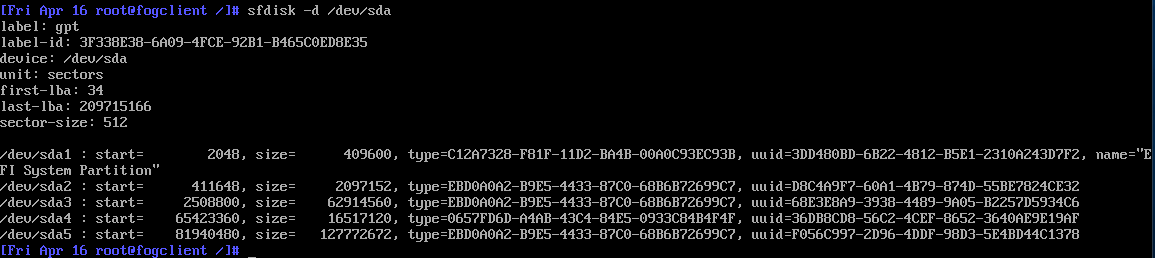
-
@Gerrit-Anderson Ok, those seem to match the ones we see in
d1.patitionsso it’s not something that is being messed up when capturing the UUIDs but looks like the IDs read/set by sfdisk are not the ones used by CentOS.While in the FOS debug command mode, run
blkid -po udev /dev/sda5, take a picture and post that here. -
@sebastian-roth Results of blkid -po udev /dev/sda5 are below!
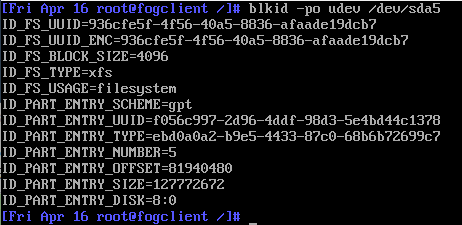
-
@Gerrit-Anderson Please tell us which UUID do you see in the CentOS /etc/fstab for this master VM machine?