How to PXE boot from master node in location/storage group
-
Hi all,
I’m hoping someone can give me some advice on how to set up FOG to boot from the master node in a given storage group/location
I’ve defined groups and nodes within those groups and also with the location plugin, but PXE booting isn’t working in a way that I’d expect.
For example purposes, the locations are defined like below:
- UK
- US
- EU
And the storage groups are defined like so:
- London
- New York
- Paris
So I’ve set it up with a master server that should provide the central management for Locations/Storage Groups/User accounts/Hosts/Images/etc. on the example IP 10.11.5.132
And there’s a Master Storage node for the London group on the example IP 10.11.5.133 which is handing out it’s own DHCP range on the subnet 10.11.17.0/24
I realise that it’s convoluted when you’re reading a text description, so here’s a diagram of the topology for this:
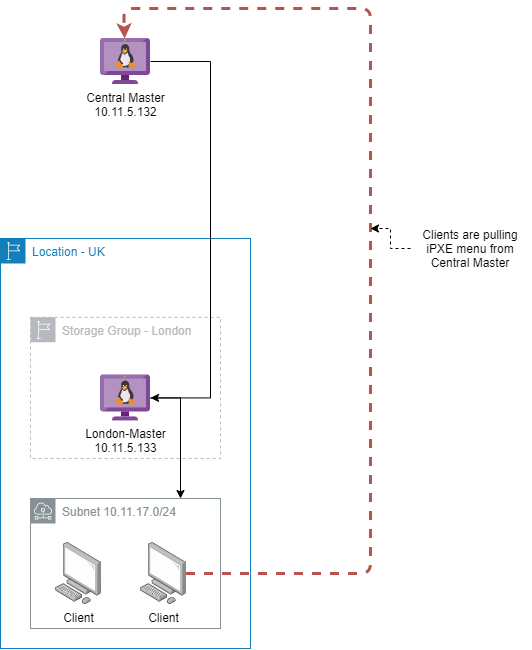
As you can see from above, the problem I’m having is that clients on the DHCP subnet for the London-Master node are still reaching out to the Central-Master server during iPXE boot. This isn’t a problem in this test environment, but we don’t want any traffic heavier than HTTP and SQL over the WAN connection when these are separated by physical sites.
In testing, I’m finding that while it’s pulling iPXE boot files from the London-Master , the boot.php file is directing it to pull the bzimage kernel from the Central Master node - shown below:
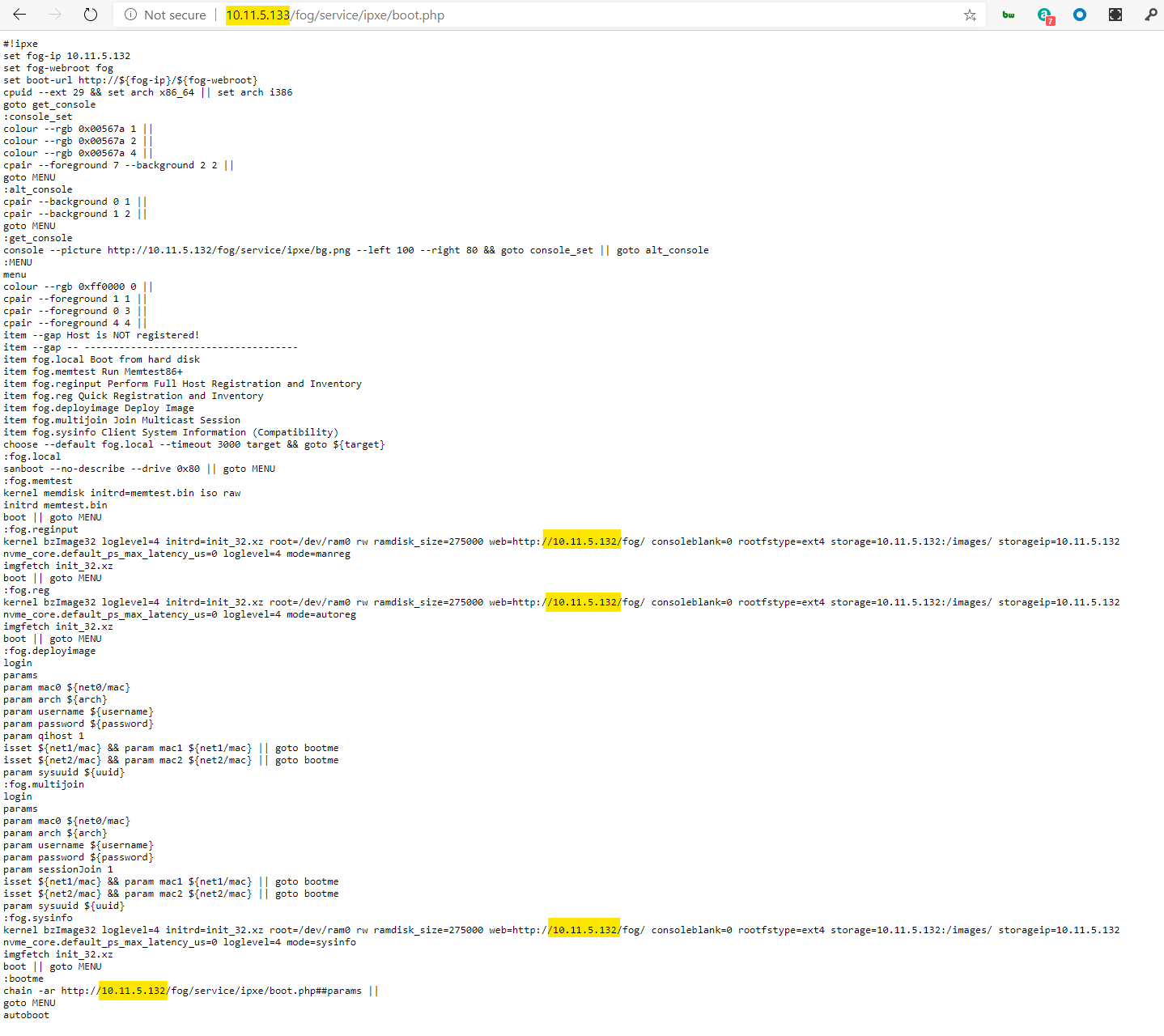
I had thought that by checking the setting ‘Use inits and kernels from this node’ for London-Master it would load bzimage from that node, yet it’s still insistent on pulling kernel files from Central-Master.
Does anyone know if what I’m describing is possible in FOG?
As a follow up - is there any way (within FOG) to get the clients shown in my diagram to use the local IP for the London-Master node on the 10.11.17.0/24 subnet rather than it’s WAN IP of 10.11.5.133 - I want this to keep the client subnet isolated as much as possible from the rest of the network. I suppose I could apply my own rules to redirect connections from 10.11.5.133 to 10.11.17.1 but it would be preferable if FOG was aware of this.
Sorry there’s a lot to unpack here, I appreciate any help that you can offer
-
Is London-master a full (normal) fog server or a storage node?
For the clients on teh 10.11.17.0/24 subnet, what is dhcp option 66 pointing to? Is it the london-master?
-
Sorry I wasn’t very clear on that, London-Master is a storage node that has isc-dhcp-server installed on it.
The DHCP next-server option is pointing to itself, client machines pick it up just fine and those services are working no problem when Central-Master is unreachable(aside from the obvious lack of connection to the SQL DB).
I suppose then the issue is more in the ‘boot.php’ file referenced in my second picture handing out what I presume to be the TFTP settings?
I’d like for that php file handed out during PXE boot to reflect that the primary FOG server is not where it should be pulling bzimage kernel files from -
@dopyrory3 Well let me tell you how its supposed to work.
(side note: I see you make reference to location, hopefully that means you have installed the location plugin or everything will pull from the master node).
First the caveats:
In a master node/storage node configuration there is only one copy of the fog database and its on the master node. All storage nodes need to be in 100% contact with the master node to reach the database. If this can’t be satisfied you will need to change your plans.All computers with the FOG Client installed must be able to reach the master node. If they can not reach the master node they will not receive new commands to install software and such.
Now to imaging:
The target computers will pxe boot in their respective subnets. They will contact what ever dhcp option 66 points to, to download ipxe boot loader. The boot loader (iPXE) contacts again what ever dhcp option 66 points to and downloads default.ipxe. That text file will point to the central FOG server to load boot.php. The boot.php script will look to see if the location plugin is installed, and then lookup what location the computer belongs to (you assign this location when you register the computer or through the webui). If the computer belongs to a location then the location plugin checks to see if there is a storage node in that location and redirects the client to get its images from that storage node.
If you have an unreliable link between the locations you might change the design and add a full fog server at each location. This will make each location a bit more standalone. You can still develop your images at the master location and have them replicated to the remote locations. The issue is from the master location you will not get a complete inventory of all of your systems since they will be registered locally at each location.
-
@dopyrory3 Two more things I want to add to what George already said:
- Image capture can only be done to a master node not to a storage node - so in your setup you would need to capture your images on the central master and wait till those get replicated to the storage node(s).
- Take another look at the text output of the boot.php you posted. See the long lines of text (also with yellow markers) starting with
kernel ...and a followingimgfetch .... Both those lines do not have a full URL on where to pull bzImage32 and init_32.xz from and therefore iPXE would prepend the URL you have in your browser location bar and pull those two binaries from there. Though on the other hand it looks kind of strange you see10.11.5.132all over the place in that output. I can imagine the location plugin (not part of the core code) having a few bugs that would need fixing to make sure even unregistered hosts get directed to the correct location’s FOG node. While I have not worked on the location plugin code too much myself I guess the location plugin main focus is on serving an image for deployment from the right location’s node.
While it might seem clear that clients in one location should only pull information from a location’s server I might say that this location node is not independent and needs to pull all the information needed from the master via SQL queries anyway.
May I ask which version of FOG you use here?
-
@george1421 Thank you so much for the step-by-step on that process, that does clear up a lot of my questions.
So the bottom line for my own deployment is the hosts will be required to pull the 8MB bzImage kernel file over WAN from the Central-Master whether I like it or not.
It’s not a very big file now that I’m really poking at it, but I’ll need to plan in advance to allow more than HTTP & SQL ports in our VPN firewall rules for remote subnets to reach the Central-Master server - probably TFTP or FTP?In terms of connectivity with the FOG client do you happen to know what protocols that’s going to need allowed? If there’s already a wiki entry you can tell me to shove off now
")
-
@dopyrory3 ok lets turn this around a bit.
Does having a central server add more value over having site specific FOG servers in your organization?
A central server would give you the ability to see and pull reports on all computers in your FOG environment. To get that from a distributed setup you would need to go to each fog server to get that info.
There are several advantages to having a distributed FOG environment in that all traffic remains within the remote sites.
Also what Sebastian mentioned, only master nodes can capture images. So in a centralized environment if a remote site needed to capture an image, it would have to send the image to the central server and not the local storage node.
Now to answer your port/protocols question.
FOG imaging uses tftp, ftp, nfs, http protocols.
The storage nodes communicate with the master node over http and mysql ports.
The FOG Client communicates over http. -
@dopyrory3 Now there is an official configuration you can use. In this configuration you have full fog servers at each location, but you develop your images at the main location and then through the FOG replicator the images will flow from the Central FOG server to the remote FOG servers.
In this configuration each site would have its own FOG server so all of the traffic would be local.
Since each site would have its own fog server, that also means that it can have its own logins (for example IT Techs from site A can’t accidentally deploy an image to site B).
Central master images are replicated to the remote fog servers.
The remote fog servers can also capture local images without conflicting with centrally supplied images.
Admin access to the remote FOG servers would be over the http protocol.
-
@george1421 Ultimately I want the real FOG server (Central-Master in this case) to be mostly used as the main administration point so the imaging actions of other admins in other countries can be monitored for usage, issues, and consistency.
I’m intending to disable the storage node features of the Central Master server so it’s not assigned to any Storage group, and let storage nodes take up the responsibility of deploy/capture for their respective countries.
This way I’m imagining I’ll be able to quickly see the imaging usage of other countries, the admins who are using it, ensure consistency of FOG versions across the network, and reduce the amount of maintenance needed in general by me to keep them all running (using the AccessControl plugin to restrict them somewhat).
I want to have nodes for countries, but centralise the management aspect .
-
@dopyrory3 said in How to PXE boot from master node in location/storage group:
so the imaging actions of other admins in other countries can be monitored for usage, issues, and consistency.
You can do this by logging into the web UIs of the FOG master nodes at each location or even easier write a little “tool” to or manually pull that information from the location (master) nodes. From my point of view there is no point in making the overall FOG setup decision depend on the reporting you want to get from the system. This should have way less priority than actual imaging and transfer of stuff over the VPN as this will cause you and your team way more issues and headaches when the initial setup decision is not ideal.
I’m intending to disable the storage node features of the Central Master server so it’s not assigned to any Storage group, and let storage nodes take up the responsibility of deploy/capture for their respective countries.
As mentioned before, capture can only be done to a master node. There is no way (other than really hacking a fair bit of the code) to get a machine to capture an image to a storage node.
using the AccessControl plugin to restrict them somewhat
Another plugin that does not belong to the core code (as all plugins do). While they are part of the official code they don’t get as much attention as the core code does. Not because we don’t like those but because we hardly have enough people to work on the core and can’t afford to put in as much energy into the plugins as we do in the core. What that means is that most plugins have been added by vigorous FOG users and we don’t have anyone to improve those as much as we work on the FOG core. When people report a bug we try to fix though. I think you get what I mean. The access control plugin is one of the most overrated in the FOG world I reckon. People hope to get a full blown access control to restrict people from anything they want them from doing but in reality FOG was not build with layers of access in mind and this plugin won’t solve it properly.
I want to have nodes for countries, but centralise the management aspect.
I think it’s really good you start looking into FOG and asking in the forums because we are keen to set you on the “right way” to enjoy using FOG a way it can really make your life a lot easier. But there are tripping hazards that we can try to rule out beforehand. So again, centralizing the management in a single Central-Master will leave you with some big hurdles to cope with. Let’s re-think that design I’d offer.