Multiple I/O Errors during imaging
-
We have been experiencing a wealth of I/O errors and nvme errors during imaging over the past few weeks. I’ll include several pictures. I’m not sure where else to look in terms of logs, as I never see any of these within the logs themselves.
We have 7 locations, each with their own FOG server. These errors have been seen at all locations. There are currently 2 locations that I am really focusing on to try and figure this out right now. Multiple systems at this point, probably in the range of 15 or more.
Images that we are attempting:
- A small typical Windows Image, about 35gb in size. Not sysprep.
- A very large image with all of our data on it, 700-800gb in size.
The errors typically occur on only the larger image as it takes much longer to apply. The smaller image can be applied in a matter of minutes, so it is less likely to occur here, although, we have seen it multiple times.
Methods of deployment:
Both unicast and multicast. Error has even occurred with just 1 at a time on both uni and multi.FOG Version: 1.5.9
All of the FOG versions were upgraded last month. I believe they were all 1.5.8. I was not apart of imaging system on the old version, but I’ve been told that none of these errors occurred prior to the upgrade. Our issue may be resolved by installing the older version, but that is something that I’d like to ask for help with. I can’t seem to find how to do that.Ubuntu OS tried and currently in use:
18.04 LTS desktop, 20.04 LTS desktop, and 20.04 LTS serverKnown Kernels tried:
4.19.145
5.10.34
5.10.50The systems are somewhat of a mix. Some are MSI B460M-Pro motherboard, while others are ASRock B360M-VDH.
All of them have the same model of drive to the best of my knowledge:
Crucial P2 2TB NVMe PCIe M.2 SSD (CT2000P2SSD8)Sometimes if this error occurs, it will only “timeout” a handful of times, and the image will continue until the end.
Sometimes, it will bring the network speed to a crawl, and will be transferring the image somewhere in the Kb/s range. At that point, we are really forced to shut it down and try again.
Sometimes when we try again, it will succeed. Sometimes, it just won’t.Currently, if I can image a single system with our larger image, it is a miracle. We have 250+ systems that we are to maintain, and we’d like to keep using FOG. Any help is appreciated!
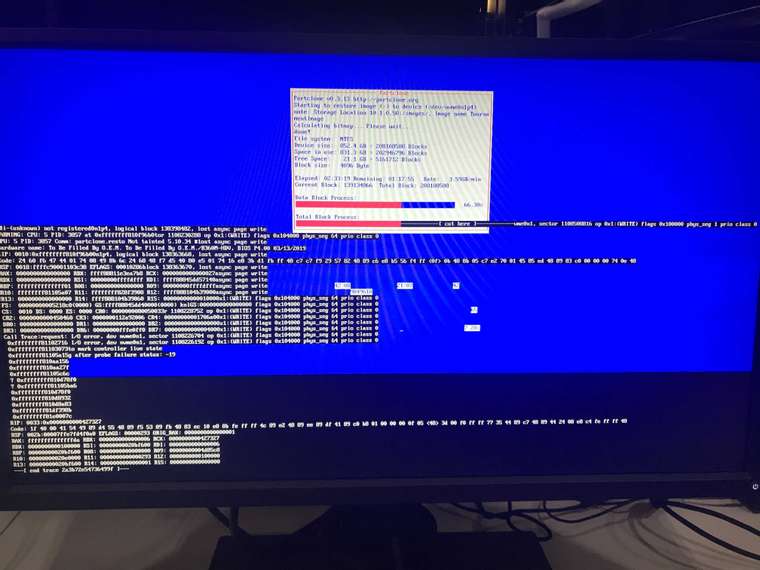
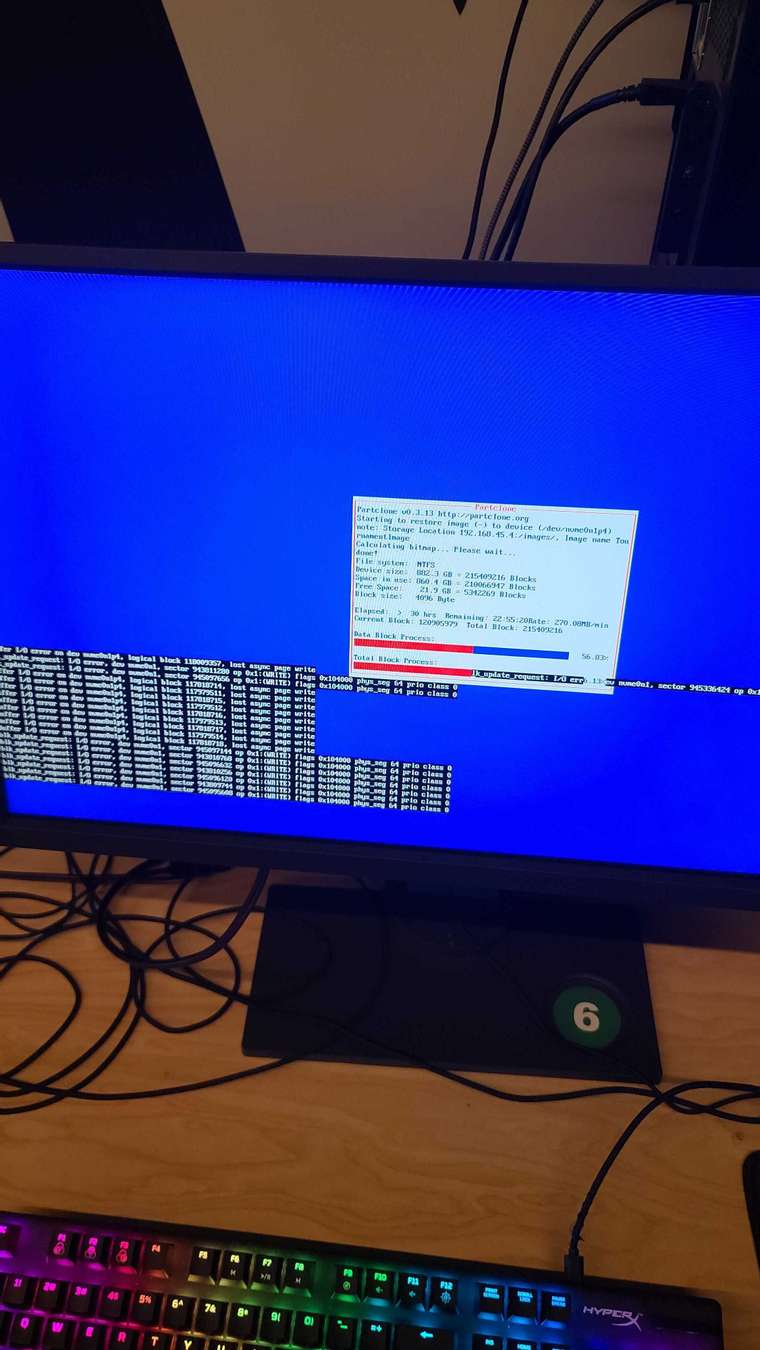
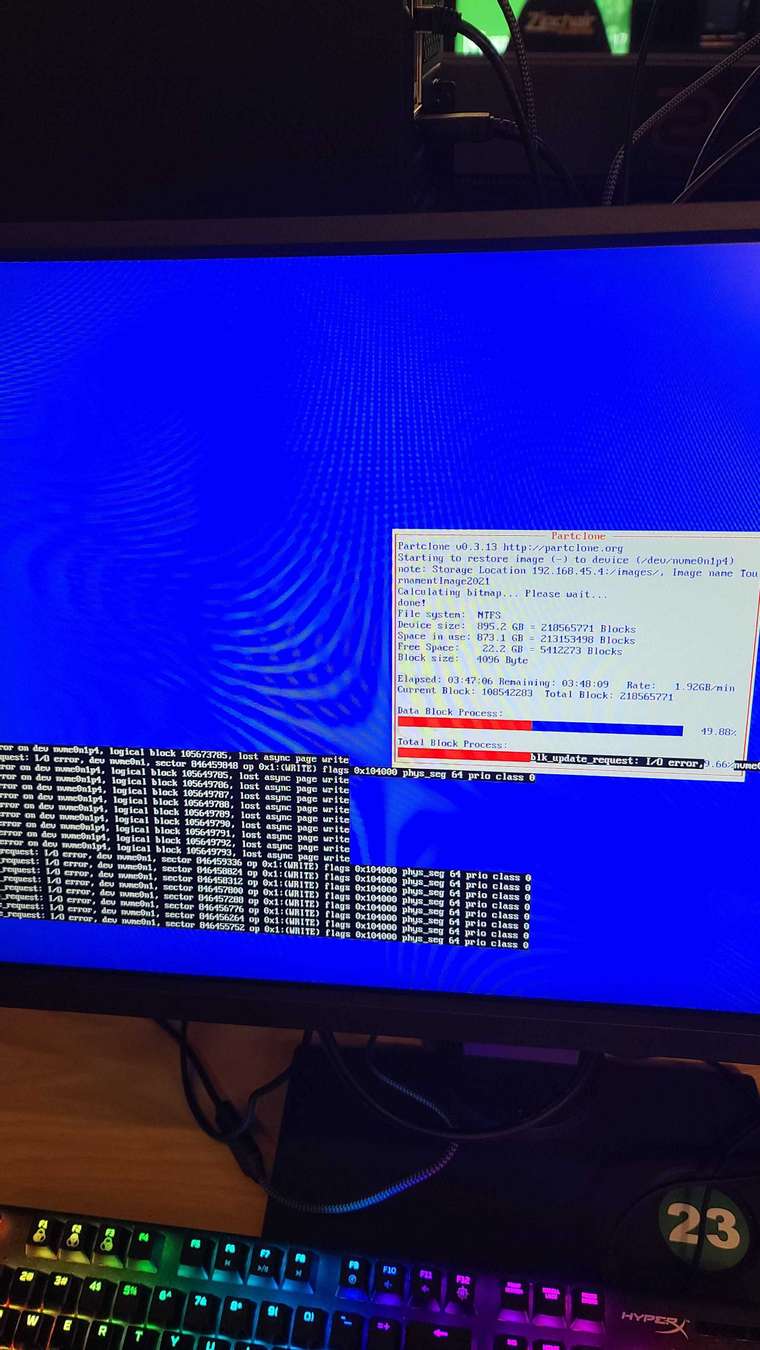
-
I’ve looked into this a bit and there are other references to this error out there. My initial reaction is this is a hardware issue, maybe specifically with the disk or mobo firmware based on the truth table so far.
You will probably need to do a bit more testing to find the root of the issue. So far no one else has reported this issue so I’m thinking it something unique to your hardware configuration. From what I’ve found from searching is basically the nvme drive is disappearing from the view of the kernel. I don’t think at the moment this is a networking issue.
The first thing I would make sure the mobo firmware is up to date.
You have already tested with a 800GB and 35GB image. I was concerned that the 800GB image was running out of resource space on the target computer, so I was going to suggest a 25GB image to see if you were getting the same error. With that 800GB image, one of the concerns about SSD/NVMe drives is sustained writes and thermal heating of the device. 800GB is going to take quite a long time of continuous writes, which is going to heat up the drive, maybe to a throttling thermal limit. I’m not saying that’s the issue, but a possibility. Even with a 25GB image, you are going to have heavy duty sustained writes for 3-4 minutes (assuming you are getting 6GB/m transfer rates in partclone). One of the down sides (if you can call it that) with FOG is that it will push the image to disk as fast as the disk can ingest the image from the fog server and force it into the disk as fast as the disk will accept it.
So the first thing (after confirming your mobo firmware is up to date) is to try swapping out that nvme disk for something like a samsung evo plus or pro. See if you get the same error.
You have tried these Crucial drives in different mobos so I don’t add a lot of value here, but try one of those drives in something like a commercial build HP/Dell/Lenovo system to see if you get the same results.
Those Crucial NVMe drives also have onboard firmware. Confirm that the firmware on the drive is current.
Right now we don’t know where the error is other than the drive appears to disappear from the linux kernel. So we need to try a few different things to see if the error moves with one of the exchanges above.
One other thing we can try is to run a deploy in debug mode (check the debug checkbox before scheduling the task). PXE boot the target computer. You will be dropped to the FOS Linux command prompt after a few pages of text. You can start imaging from the command prompt by keying in
fog. Proceed with imaging step by step until you get the error. Press Ctrl-C to get back to the command prompt. From there look at the messages in /var/log (syslog or messages, I can’t remember ATM). See if there is any clues at the end of the log that might give us an idea. This command might give us a clouegrep nvme /var/log/syslogAlso after you get that error and get back to the FOS Linux command prompt key in
lsblkto see if the drive really went away. -
@george1421
Thank you for the feedback!I’ve taken your advice and since tested with a MB BIOS flash and a firmware update on the P2 drives (there was one available), and also a few different FOG kernels just in case. Same results with all of that.
I currently have 2 systems that just won’t take this large image with the P2 drives, so I was able to use the same systems and do a multicast on 1TB SSD’s instead. That passed with flying colors.
We don’t have any commercial build systems here, but we do have a different model of M.2 drive, so I’m currently testing with that.
I wasn’t able to get the debug mode to work just yet, but I’ll give that a try again after this different model of M.2 testing. I’ll provide an update to my testing.
Another part of the truth table though, is that all of these Crucial P2 drives were actually imaged with a ~1TB image many months ago when they were initially installed. Most locations were brand new systems with these drives, but we also have one location that has older model systems (B360M chipset) where we just upgraded the M.2 drive to these Crucials. To the best of my knowledge, the first round of imaging did not produce any of these issues, which is about 250+ systems. It wasn’t until the 2nd, and some 3rd round that these issues started to occur.
-
@dmcadams said in Multiple I/O Errors during imaging:
I wasn’t able to get the debug mode to work just yet, but I’ll give that a try again after this different model of M.2 testing. I’ll provide an update to my testing.
If you use the normal FOG PXE bootup it’s very simple to get into debug. Go to the FOG web UI and choose Basic Tasks for a single host (debug in multicast mode is not available). Click deployment and then there is a checkbox for debug just before you hit the “Create Task” button.
From what we know so far, could it be the Crucial drives are kind of worn out to a degree that makes them drop out on high load like deployment of an image (large and some even on the smaller image)?
-
@george1421 said in Multiple I/O Errors during imaging:
One other thing we can try is to run a deploy in debug mode (check the debug checkbox before scheduling the task). PXE boot the target computer. You will be dropped to the FOS Linux command prompt after a few pages of text. You can start imaging from the command prompt by keying in fog. Proceed with imaging step by step until you get the error. Press Ctrl-C to get back to the command prompt. From there look at the messages in /var/log (syslog or messages, I can’t remember ATM). See if there is any clues at the end of the log that might give us an idea. This command might give us a cloue grep nvme /var/log/syslog
Also after you get that error and get back to the FOS Linux command prompt key in lsblk to see if the drive really went away.Could you help explain how to proceed with imaging step by step while in debug mode? I can get there, and keyed in fog to receive the variables, I’m just not sure of what the syntax would be to begin a unicast image, or what else I’m missing here.
-
@dmcadams If you schedule a task, but before hitting the schedule task button select debug option then schedule the task.
That will drop you at the FOS Linux command prompt. You key in
fogthen it will start imaging up to a break point. At the break point the script will pause waiting for you to press the enter key to advance to the next step/break point. You will need to hit the enter key to proceed through the entire imaging process. Hopefully you will see a useful error during imaging that will give us a clue to the root of the issue. -
@george1421
Sure enough there are massive errors. Sorry, I don’t know how to export that from my client and paste it here. I tried to capture it within pictures, and just grab the majority of different errors seen. Also note in the last one, I did the lsblk command with no results shown.
-
@dmcadams There is an interesting topic about this on the web: https://forums.unraid.net/topic/92924-solved-sudden-problems-when-starting-vms/
Same error messages, Cricial NVME SSD, … but other users report this for other drives as well. Seems like you can try to work on this by cooling drive and controller but heavy I/O will cause it again most probably.
He got it solved in the end:
Months after replacing the Crucial drive with a Samsung 970 Evo, I’m pleased to say this issue has not happened since. Not even once.
I am wondering if you can work around this by throtteling partclone throughput. A simple throttle would be to install an old 100 MBit/s switch between PC and the rest of your network. But the large image would take ages then.
Just found this other topic on the web. Though I am not sure this applies in your case: https://forum.level1techs.com/t/fixing-slow-nvme-raid-performance-on-epyc/151909/13
Another part of the truth table though, is that all of these Crucial P2 drives were actually imaged with a ~1TB image many months ago when they were initially installed.
Maybe this way using an older kernel. You can try manually downloading older kernels from our website. Put into
/var/www/html/fog/service/ipxe/and set Host Kernel to the older kernel filename on a specific host (host’s settings in the FOG web UI) for testing. -
Another part of the truth table though, is that all of these Crucial P2 drives were actually imaged with a ~1TB image many months ago when they were initially installed.
Maybe this way using an older kernel. You can try manually downloading older kernels from our website. Put into
/var/www/html/fog/service/ipxe/and set Host Kernel to the older kernel filename on a specific host (host’s settings in the FOG web UI) for testing.@Sebastian-Roth So I’m trying the easy things first. I have a system that just would not image to the P2 drive at all. Always throwing errors within a short time. This system works great with a 2.5" SSD, and also a different model of M.2 NVMe drive (ADATA 1TB). I installed an M.2 heatsink on the P2 and got the same errors. So…
I went down the old kernel path like you suggested and found a kernel that not only worked on a drive that previously failed over and over, but it also didn’t produce any errors, and maintained great speeds (under 2hrs for a 800gb image). I had to try a few kernels before finding one that would even boot without a kernel panic, but finally landed on 4.19.6 (64bit). Is there anything that makes sense about why this kernel would work? Maybe it isn’t reading the temperatures correctly (or it is?) so its not throwing the I/O errors? What are your thoughts? -
@dmcadams Sorry for the late reply but I’ve had too much on my table this week and couldn’t find the time to think through this again.
Great you tested different kernels and found one working fine. Short answer is, name this kernel binary different to the default Kernel naming theme, e.g. bzImage-4.19.6 or whatever suites you and set this name as Host Kernel in each host’s settings having this issue. Make sure you update the general kernel to the latest via FOG settings again so all your other machines will use the new one.
The longer answer is: With that new information I don’t think it’s a temperature issue really. Sounds like this kicks in with a certain Kernel version probably because it has some new driver or feature added that is causing this. Often some new features (e.g. NVMe optimization or so) are implemented differently by various vendors. While drives from vendor A might go with it just fine some other vendor uses a different code in its firmware causing a problem in the Linux kernel.
If you are really keen we can go and test each kernel version one by one to find what’s causing it and possibly find a solution (special kernel parameter or a patch for the code). Though this will need work and time. I can give you many hints and instructions but it’s your call to work on it. Compiling kernel after kernel (very easy to do) and testing each while keeping close track of the results to find it. It really needs determination to stick with it. But you will learn a lot I am sure.