Deploy with Multicast on different machines
-
@seppim This is the partition table you posted earlier from the Ubuntu system directly:
Device Start End Sectors Size Type /dev/sda1 2048 4095 2048 1M BIOS boot /dev/sda2 4096 2101247 2097152 1G Linux filesystem /dev/sda3 2101248 20969471 18868224 9G Linux filesystemWhile the information of the first partition (sda1) matches the later ones don’t. Size of sda2 and therefore start of sda3 are way larger than what you posted before.
Let’s do the math: In the header you see
last-lba: 3907029134which essentially means the last sector on disk. 3907029134 * 512 byte sector size / 1024 / 1024 / 1024 / 1024 = 1.819 terabyte. -> This particular image was captured from a huge disk!There are two important things you need to know about:
- As of now FOG does not move partitions on the disk. So even if it can shrink sda2 in your case it won’t move sda3 forward. We are working on this restriction but it’s now in production yet. If you are keen to test what we have so far, let me know.
- FOG does not recognize LVM properly and I can’t promise you to work at all times. Proper LVM support has been discussed but we never got to implement that.
So I suggest you re-capture your image from the initial install (sda2 being 1 GB in size) so you can deploy that image again. As well you might think about your partition layout and using LVM. Do you use LVM for a particular reason?
-
@sebastian-roth Hi Sebastian,
ok, this is a little weird … I try to capture again the Ubuntu Server 20 from my Virtual Box. HDD size 10GB.
Not possible … seems not enough storage.
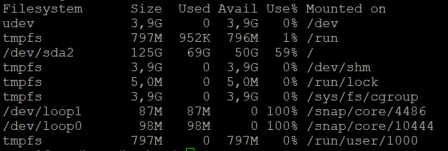
But there are 50GB free:
Fog server:
Capture error:
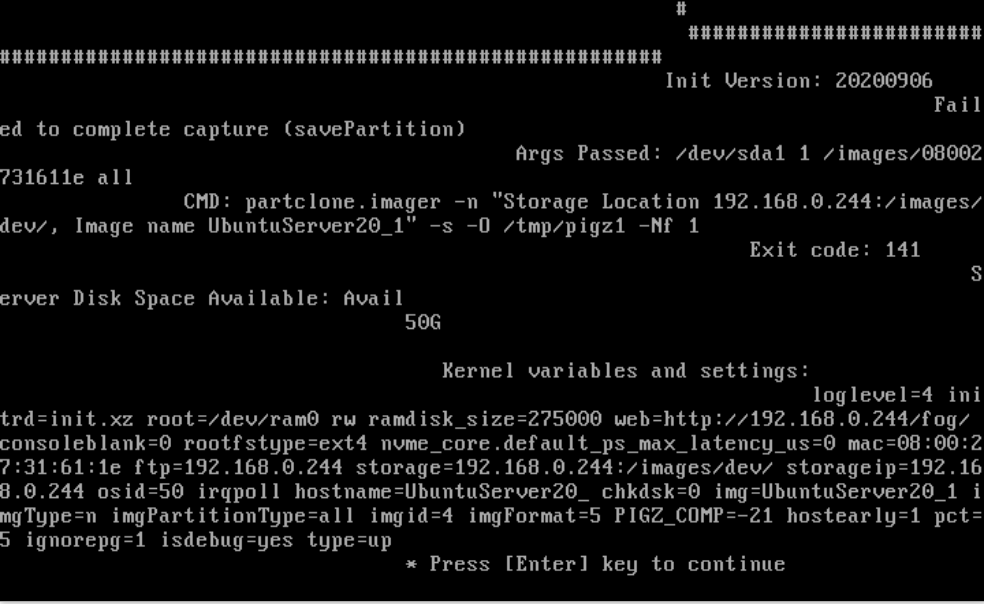
I´m not able to continue in debug mode … when I press Enter: nothing happens
-
@seppim This is just an idea, in the image definition UbuntuServer20_1 lower your image compression to 11 and see if you can upload then. If you are using zstd with a compression of 21 that will take a lot of RAM on the target computer.
Just out of curiosity how much RAM does this capture computer have?
Also looking at this I’m not sure why pigz_comp == -21 that just seems wrong. One might think that should be a positive integer value.
-
@seppim We are jumping from one issue to the next here and I am not sure I can follow.
The disk space available message at the end of this error is just a “blind hint” as we had users in the past that ran into an issue just because of disk space and we added this information to the error message. Doesn’t mean this is the actual cause in your case. Obviously not if your image is just around 10 GB. We would need to see if there is a preceding error. Best if you schedule the capture as debug and when you get back to the shell after the error you should find some information in
/var/log/partclone.log(on this host you capture from).There is more I find strange in this picture. Why is it using
partclone.imagerfor/dev/sda1? That would mean FOG cannot detect the filesystem on this partition. Shouldn’t that be the VFAT/FAT32 formated UEFI boot partition? -
@sebastian-roth Hello,
capture is now running … sorry, guess it was my fault?
I thought to use the latest kernel … but the list in the kernel module is not sorted by the newest. So I install 4.19.143 … I see this now and install now 5.6.18
I also set the compression back … its now capturing!
Sorry for the second issue … I try to capture and deploy on the physical and virtual PC and check if with multicast the problem stil exists (physical is resizing and virtual continue deploy)
-
@sebastian-roth ok, deploy is now running.
To set the timeout from 10 to 300 helps. The VM is waiting while the physical PC resizing /dev/sda2.
PC: 250GB HDD
VM: 10GB HDDBoth booting after deploy! Great
-
@seppim Unfortunately you changed 2 things at the same time so its unclear what fixed the partclone.imager problem. The kernel updates should have only have addressed new hardware.
Would you mind making a second test capture (to a new image definition) with the compression set back to 21 with the 5.x kernel installed. This is a unique error and we need to find what really fixed the problem. As you follow Sebastian’s debug test. You are not the first person to hit upon this issue.
Also how much ram is installed in this computer? 4GB?
-
@george1421 Hello!
Sure, no problem … from which PC you need to know the RAM?
Master VM: 1024MB
FOG server in Hyper-V: 2834MBI try to capture again.
edit:
yes, error:
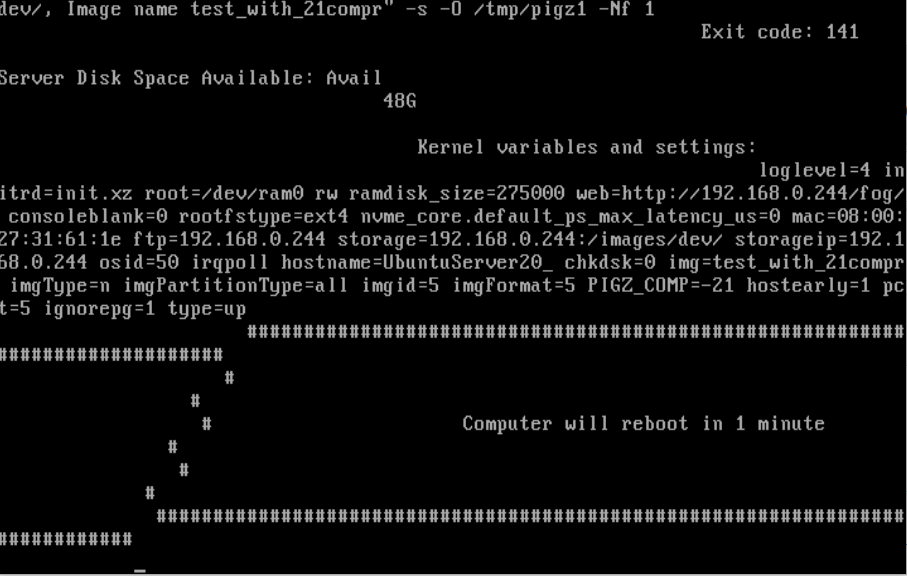
edit 2:
I set the Compression back to 18 … then he start capturingedit 3:
until compression 20 its working here … 21 and 22 throw erroredit 4:
no, after some time, he reboots … maybe running out of memory … but now error while startup the capturing -
@seppim Ok from your testing with 1GB of ram any compression over 19 with a 30GB (data) capture size it fails.
The issue with zstd compression (not an issue but a fact) is that zstd is a very good data compressor but it takes more RAM with the higher compression values. This is because it needs to buffer more of the image into memory to be able to sample more data to squeeze it down. My bet is if your pxe booting system would have 4GB of ram this issue would not appear at the compression of 21.
We are all learning here too, that is why its important to have people like you willing to help find the problem for the next guy.
-
@george1421 Hello!
ok, thank you. I have with this case now other questions. I don´t open a new post and asking here:
- I deploy a group via multicast (12 PC´s). Unfortunately one PC (PC07) has an another HDD and this was to small. So all other 11 PC´s waiting for this PC07 to start the deploy. But PC07 never start and I need to cancel all.
1.1 Is it possible, to cancel just one or more PC while the other are waiting? When I check PC07 and click cancel task … he stop the multicast and all PC´s are canceled - When I want to deploy a group … and some of the PC´s I want to exclude this one time … is this possible? He deploy always all PC´s and when I cancel some in the task, he cancel all (same as point 1)
- Update the Windows product key: I deploy a image, where the product key from the master is set. sysprep I don´t used, because after the PC are nor started. When I manual set the new product key in Windows and click activate, it is working. Can I set this also with FOG? I can add the product key in the host settings … but when and how I can write this to the client?
- While a multicast deploy to the 11 PCs, one was stopping (because of hardware problem) … but then all other 10 also stopping, because one of the PC was “lost” while write sda3 … can I manual delete this one problem PC, so that the other continue the multicast deployment?
Thank you!
All in all did the FOG server a great job and at least all 12 PC´s was deployed … but next time I want this faster, when I can handle the problems
")
- I deploy a group via multicast (12 PC´s). Unfortunately one PC (PC07) has an another HDD and this was to small. So all other 11 PC´s waiting for this PC07 to start the deploy. But PC07 never start and I need to cancel all.
-
@seppim said in Deploy with Multicast on different machines:
Is it possible, to cancel just one or more PC while the other are waiting? When I check PC07 and click cancel task … he stop the multicast and all PC´s are canceled
You just need to wait for 5 minutes and the multicast will begin without PC07.
-
@seppim To slightly expand on what Sebastian just posted.
With the multicaster there are 2 triggers to start the imaging process.
- Number of clients
- Timeout
With 1. If you set it to 4 clients, as soon as the 4th client connects imaging will start.
With 2. If you set it to 3 minutes. Imaging will start at 3 minutes even if all of the clients haven’t checked in yet.
-
There is no way to selectively skip a target computer when deploying to a group. You are either in or out of the group when deployment is requested.
-
Windows product key. Can you do this with FOG? Yes. Can you do this without sysprep, not easily. If you use sysprep then you can write the key into the unattend.xml file that is used during the first boot. Without sysprep you can still do something like during imaging write the key to a file on the c drive then in your golden image before capture created a scheduled task that runs at login to read that file dropped by FOG and activate the system.
-
If one of the group fails. After a timeout the others should continue on. That is what I think is the imaging flow. All should not wait forever for that lost computer to wake up.
-
@sebastian-roth oh, ok
Thank you!