Thanks everyone for chiming in. Let me try to address everything below:
@Wayne-Workman said in One FOG server with multiple storage nodes?:
I think what you’ve tried is very close.
So, each IP address for each NIC should have a storage node defined. It’s fine to point them all to the same local directory. In such a scenario, all the nodes need to belong to the same group. For Multicasting to work (don’t know if you’re using that), one node in the group must be set as Master.
Could it be firewall?
Are there any apache error logs?
Another thing to do - and this will really help you out - is to do a debug deployment with the multiple NICs and corresponding storage nodes setup, and then to manually do the NFS mounting yourself and see how that goes, see what errors you get, and so on. We have a walk-through on this right here:
https://wiki.fogproject.org/wiki/index.php?title=Troubleshoot_NFS
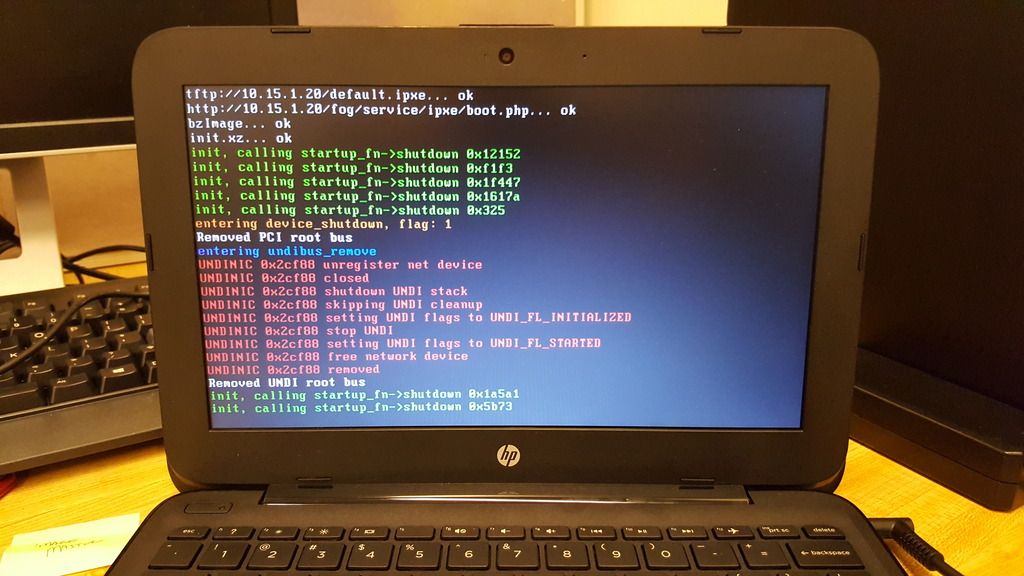
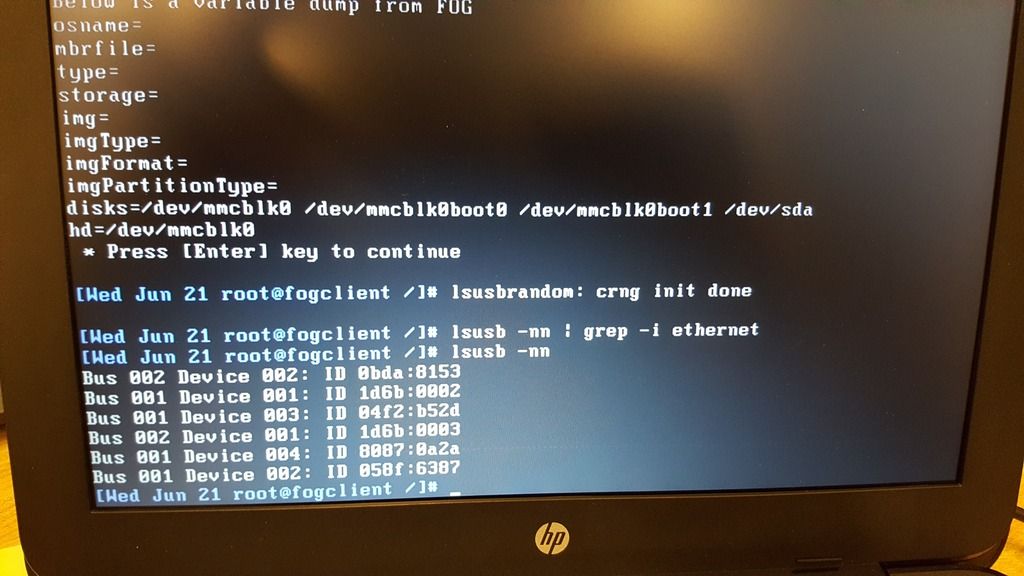
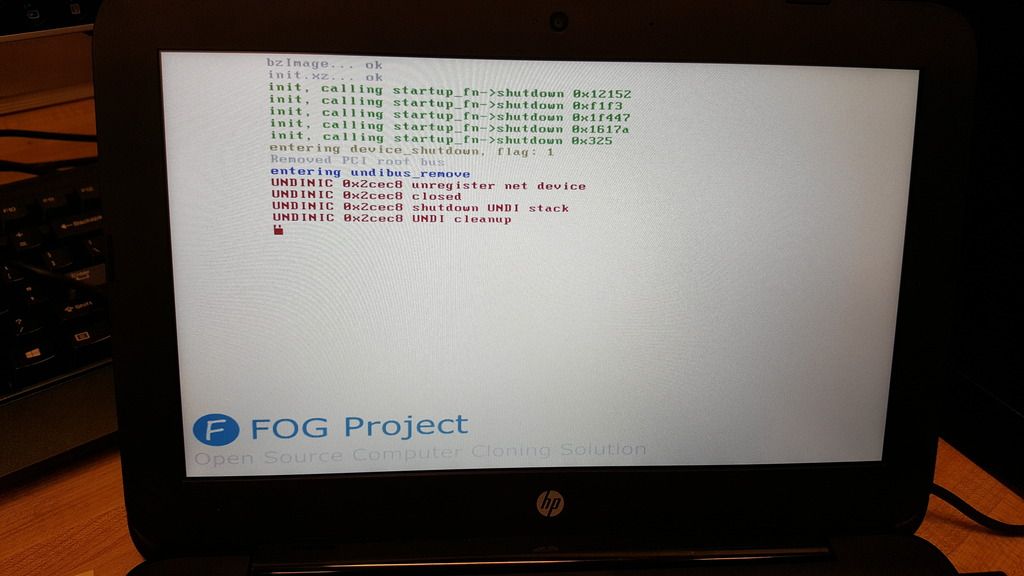
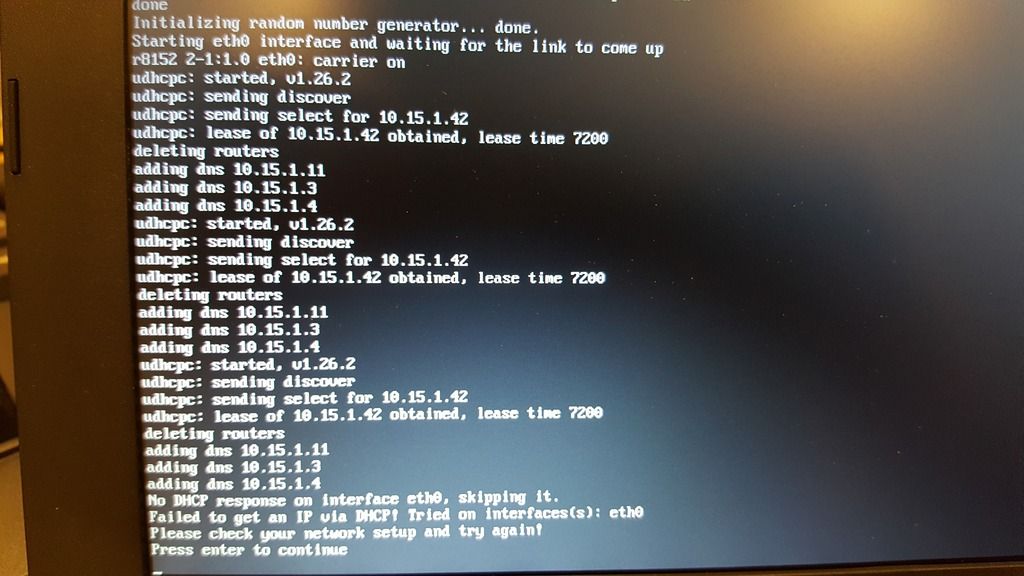
Please report back with your findings, be they failure or success. Screen shots of any errors would immensely help out.
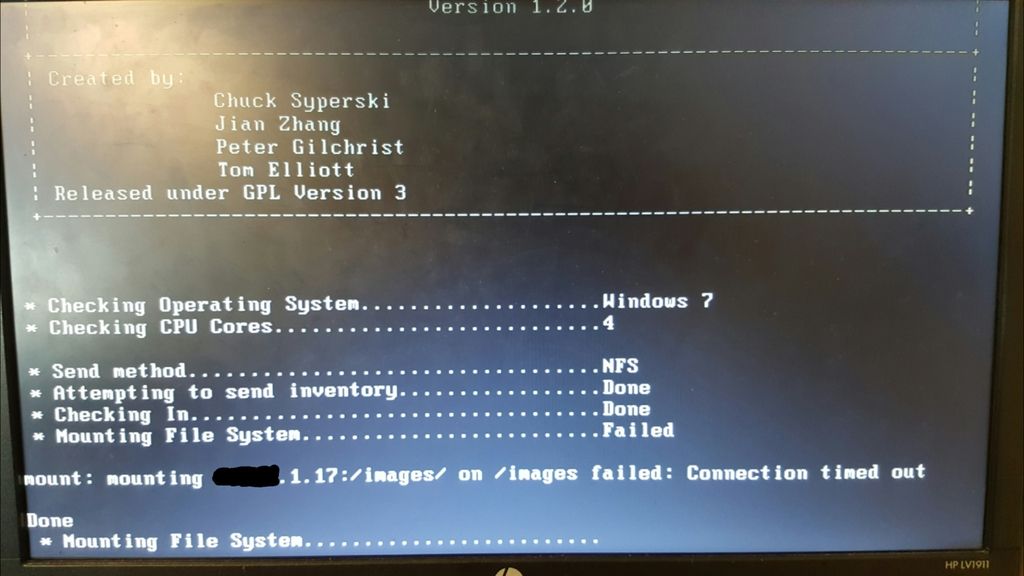
Yep, each new storage node I added I assigned the same static IP that I gave the particular interface in the OS. Only the default was set as master, and they were all part of the default group. The original IP of the server is x.x.1.20; the two storage nodes I added were 1.17 and 1.18, respectively. When I tried imaging with this configuration, it booted fine and got to the point where it had started to prep the disk to pull the image from the storage node, then just complained that accessing the 1.18 node kept timing out.
The first thing I did was disable the firewall (sudo ufw disable) but saw no change. When I disabled the other two interfaces (1.20 and 1.17) to make sure that I could at least get internet traffic on the server, it started imaging. And as soon as I reenabled one of the other interfaces, it stopped immediately.
I didn’t check any logs, though I will have a look at this again and see what I can come up with based on your suggestions.
@ITSolutions said in One FOG server with multiple storage nodes?:
What mode of bonding did you setup when you did the test? Also did you make sure each virtual NIC was assigned to different physical NIC’s?
I followed the instructions here more or less to-the-letter: https://wiki.fogproject.org/wiki/index.php/Bonding_Multiple_NICs
I used bond mode 2 and gave the bond interface the same MAC of the old eth0 NIC as reported by ifconfig. What I would have had in the interfaces file would have been similar to this:
auto lo
iface lo inet loopback
auto bond0
iface bond0 inet static
bond-slaves none
bond-mode 2
bond-miimon 100
address x.x.1.20
netmask 255.255.255.0
network x.x.1.0
broadcast x.x.1.255
gateway x.x.1.1
hwaddress ether MAC:OF:ETH0
auto eth0
iface eth0 inet manual
bond-master bond0
bond-primary eth0 eth1 eth2 eth3
auto eth1
iface eth1 inet manual
bond-master bond0
bond-primary eth0 eth1 eth2 eth3
auto eth2
iface eth2 inet manual
bond-master bond0
bond-primary eth0 eth1 eth2 eth3
auto eth3
iface eth3 inet manual
bond-master bond0
bond-primary eth0 eth1 eth2 eth3
@george1421 said in One FOG server with multiple storage nodes?:
let me see if I understand this.
You have a ESXi server and it has 4 nic cards that are trunked to your core switch. From the core switch to the remote idf closets you have (2) 4Gb links (!!suspect!!). Your fog server has one virtual nic (eth0)
Some questions I have
- Your ether channel trunk did you use lacp on that link and is your link mode ip hash or mac hash (the esxi server and the switch need to agree on this)?
- You stated that you have 4Gb link to the idf closets? Are you using tokenring or fiber channel here?
- When you setup your fog vm, what (ESXi) style network adapter did you choose (VMXNet, or E1000)? For that OS you should be using E1000.
- What is your single client transfer rate according to partclone?
I can tell you I have a similar setup in that I have a ESXi server with 4 nics teamed with a 2 port LAG group to each idf closet. In my office I have an 8 port managed switch that I use for testing target host deployment, that is connected to the idf closet and the idf closet to the core switch.
For a single host deployment from the fog server to a Dell 990 I get about 6.1GB/min which translates to about 101MB/s (which is near the theoretical GbE speed of 125MB/s)
The physical setup is the ESX(i) server with 4x 1Gb NICs in port-channel (not trunked, all access ports and all IPs on the VMs are on the same vlan) to a Cisco 2960x stack (feeds the labs I was working in, so no “practical” throughput limits here between switches), which has 2x 1Gb LACP links to the core switch (an old 4006). From there, there are 2x 1Gb MM fiber links to 2960X stacks in the IDFs (again, LACP); there is a 3x MM LH fiber link to a building under the parking lot (PAGP port channel due to ancient code running on the 4006 at that building). There is a remote site with a 100 Mb link through the ISP (it kills me) but FOG is not used there currently.
ESXi is using IP hash load balancing - basically identical to the config here: https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=1004048
I will double check on what NICs VMware is emulating to the OS. When I gave the VM four NICs, it was just VMNIC1, VMNIC2, etc.
I usually see a transfer rate (as was noted by another poster, after decompression) of a little over 4 GB/min on older Conroe based CPU hardware (which is the bulk of what is at this site) - I can do that on up to 4 hosts simultaneously before it drops into the high 3s, at which point I can see the saturation of the NIC in the FOG console home page’s transmit graph (125 MB/s). The newest machines there I saw a transfer rate as high as 6.65 GB/min (Ivy Bridge i5s) but have yet to try sending more than one of those at a time. All the image compression settings are default.