Deploy with Multicast on different machines
-
Hello,
I´m new with FOG and so far its running fine.
I tried now to deploy a Ubuntu server 20 to a Virtual Box and one physical PC.
The first partition he deploy simultaneous.
But as the 9.7Gb partition was to write, the physical PC resize the partition while the VM are already start with the next.
So the PC wait after resizing while the VM already write the next.
At the End, the VM was deployed and the PC still waiting.
Is this a bug or did I made something wrong?
Thank you!
-
@seppim Which version of FOG do you use? Is the disk size between physical machine and VM different? Just wondering if it takes way longer on the physical machine!?
The udpcast used for multicasting waits for as many machines as you told it to deploy (two in this case) on each partition and should not start the next partition earlier unless a timeout of 10 seconds between partitions is reached.
I can imagine that in your case the 10 seconds are too little of wait time between partitions. You can change that value of 10 seconds in the code only. Edit file
/var/www/html/fog/lib/service/multicasttask.class.phpline 659 and increase the value as you wish. Wait for all tasks to finish or cancel those and restart your FOG server to apply this change (service restart would do as well but I just want to make sure all multicast sessions are cleaned up). -
This post is deleted! -
I’m using 1.5.9
Yes, in the VM I set 128GB and the physical PC had 250GB.
The timout with 10sec sounds good and test is today again. The resizing on the physical PC take for sure longer … on the VM I did not see any resizing.
-
I try it again, but get an error in the VM. The PC are correct booting and waiting.
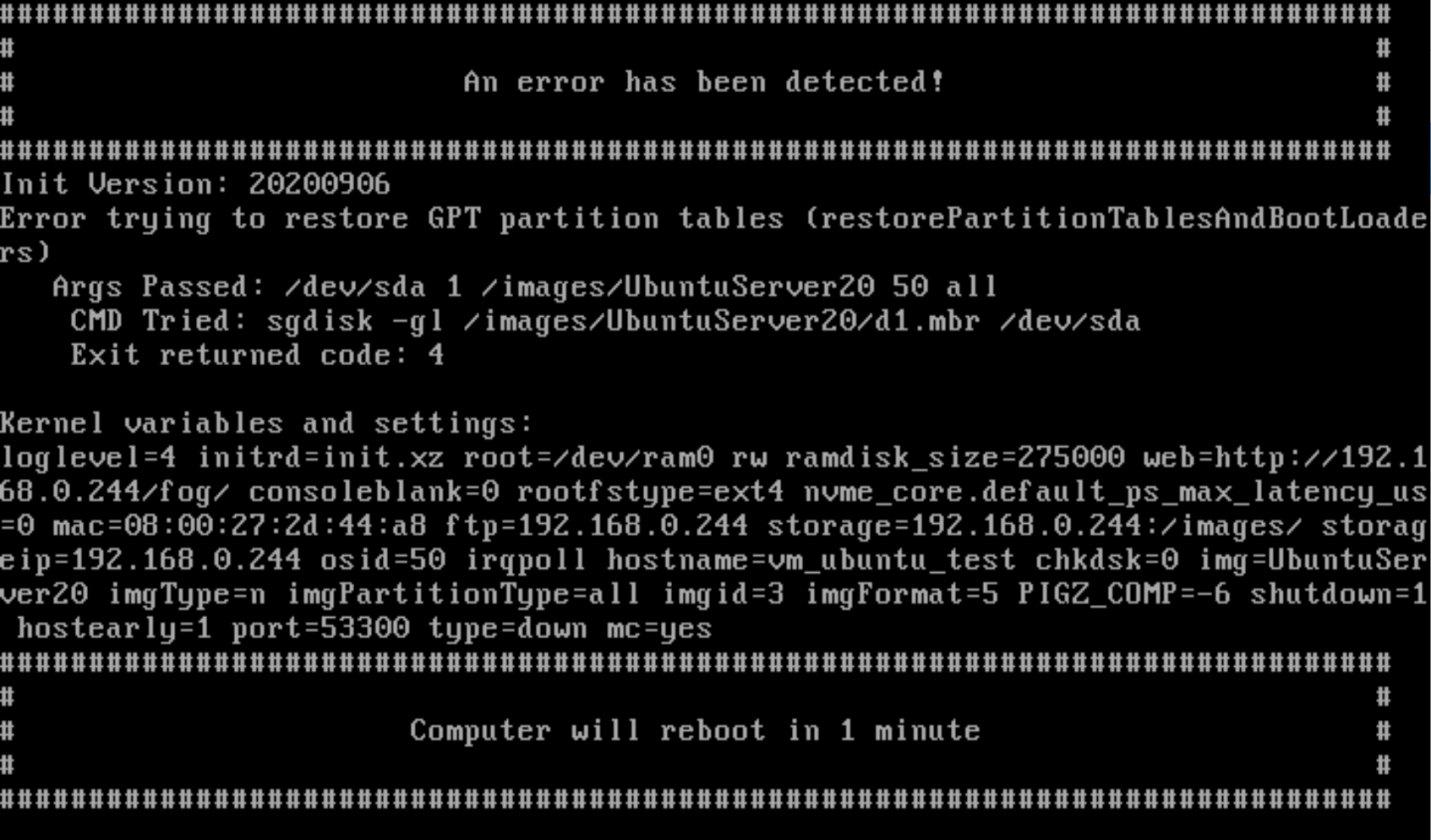
I deleted the HDD from the VM and setup new, but same error.
Erasing GPT is done, but then I get this error -
@seppim What does the original partition layout in your Ubuntu install look like? Please run the following commands on your Ubuntu master install that you capture from and post results here:
lsblk fdisk -l mount lvscanAbout the error: I guess the disk size in the VM is too small to deploy this particular image to. What size is the VM disk?
-
Both has 10GB HDD … I already deploy once to a VM … so this is weird.
I think between this I made on the FOG Server a apt upgrade.
lsblk:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT loop0 7:0 0 55M 1 loop /snap/core18/1880 loop1 7:1 0 55.4M 1 loop /snap/core18/1932 loop2 7:2 0 67.8M 1 loop /snap/lxd/18150 loop3 7:3 0 71.3M 1 loop /snap/lxd/16099 loop4 7:4 0 31.1M 1 loop /snap/snapd/10492 loop5 7:5 0 29.9M 1 loop /snap/snapd/8542 sda 8:0 0 10G 0 disk ├─sda1 8:1 0 1M 0 part ├─sda2 8:2 0 1G 0 part /boot └─sda3 8:3 0 9G 0 part └─ubuntu--vg-ubuntu--lv 253:0 0 9G 0 lvm / sr0 11:0 1 1024M 0 romfdisk -l
Disk /dev/loop0: 54.98 MiB, 57626624 bytes, 112552 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk /dev/loop1: 55.37 MiB, 58052608 bytes, 113384 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk /dev/loop2: 67.77 MiB, 71041024 bytes, 138752 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk /dev/loop3: 71.28 MiB, 74735616 bytes, 145968 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk /dev/loop4: 31.6 MiB, 32571392 bytes, 63616 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk /dev/loop5: 29.9 MiB, 31334400 bytes, 61200 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk /dev/sda: 10 GiB, 10737418240 bytes, 20971520 sectors Disk model: VBOX HARDDISK Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: gpt Disk identifier: 01BDEC12-F9A1-4F00-BFC2-2B10AFF0D320 Device Start End Sectors Size Type /dev/sda1 2048 4095 2048 1M BIOS boot /dev/sda2 4096 2101247 2097152 1G Linux filesystem /dev/sda3 2101248 20969471 18868224 9G Linux filesystem Disk /dev/mapper/ubuntu--vg-ubuntu--lv: 8.102 GiB, 9659482112 bytes, 18866176 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytesmount:
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime) proc on /proc type proc (rw,nosuid,nodev,noexec,relatime) udev on /dev type devtmpfs (rw,nosuid,noexec,relatime,size=458144k,nr_inodes=114536,mode=755) devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000) tmpfs on /run type tmpfs (rw,nosuid,nodev,noexec,relatime,size=100416k,mode=755) /dev/mapper/ubuntu--vg-ubuntu--lv on / type ext4 (rw,relatime) securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime) tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev) tmpfs on /run/lock type tmpfs (rw,nosuid,nodev,noexec,relatime,size=5120k) tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755) cgroup2 on /sys/fs/cgroup/unified type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate) cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd) pstore on /sys/fs/pstore type pstore (rw,nosuid,nodev,noexec,relatime) none on /sys/fs/bpf type bpf (rw,nosuid,nodev,noexec,relatime,mode=700) cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio) cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb) cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct) cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event) cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices) cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer) cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids) systemd-1 on /proc/sys/fs/binfmt_misc type autofs (rw,relatime,fd=28,pgrp=1,timeout=0,minproto=5,maxproto=5,direct,pipe_ino=15888) hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime,pagesize=2M) mqueue on /dev/mqueue type mqueue (rw,nosuid,nodev,noexec,relatime) debugfs on /sys/kernel/debug type debugfs (rw,nosuid,nodev,noexec,relatime) tracefs on /sys/kernel/tracing type tracefs (rw,nosuid,nodev,noexec,relatime) fusectl on /sys/fs/fuse/connections type fusectl (rw,nosuid,nodev,noexec,relatime) configfs on /sys/kernel/config type configfs (rw,nosuid,nodev,noexec,relatime) /dev/sda2 on /boot type ext4 (rw,relatime) /var/lib/snapd/snaps/core18_1880.snap on /snap/core18/1880 type squashfs (ro,nodev,relatime,x-gdu.hide) /var/lib/snapd/snaps/core18_1932.snap on /snap/core18/1932 type squashfs (ro,nodev,relatime,x-gdu.hide) /var/lib/snapd/snaps/lxd_18150.snap on /snap/lxd/18150 type squashfs (ro,nodev,relatime,x-gdu.hide) /var/lib/snapd/snaps/lxd_16099.snap on /snap/lxd/16099 type squashfs (ro,nodev,relatime,x-gdu.hide) /var/lib/snapd/snaps/snapd_10492.snap on /snap/snapd/10492 type squashfs (ro,nodev,relatime,x-gdu.hide) /var/lib/snapd/snaps/snapd_8542.snap on /snap/snapd/8542 type squashfs (ro,nodev,relatime,x-gdu.hide) tmpfs on /run/snapd/ns type tmpfs (rw,nosuid,nodev,noexec,relatime,size=100416k,mode=755) nsfs on /run/snapd/ns/lxd.mnt type nsfs (rw) tmpfs on /run/user/1000 type tmpfs (rw,nosuid,nodev,relatime,size=100412k,mode=700,uid=1000,gid=1000)lvscan:
ACTIVE '/dev/ubuntu-vg/ubuntu-lv' [<9.00 GiB] inherit -
@seppim Is you image set to “Single Disk - resizable”? FOG does not handle the LVM properly so I cannot imagine why this partition layout would do resize operations on the physical machine?!?!
To find out why you get the error the best way is to schedule a deploy task as debug - same as when you schedule a normal unicast deploy to the VM but just before you click the “Create Task” button there is a checkbox for debug. Start up the VM as normal and you should get to a command shell. There you fire off the command
fogto start the debug deploy and step through it. Then when it prints the error message you get back to the command shell. Run this command manually and take a picture of the messages on screen to post here:sgdisk -gl /images/UbuntuServer20/d1.mbr /dev/sda -
@sebastian-roth I did now the debug deploy and he show me: size to small.
So I set from 10GB to 14GB (Master has 10GB) and did a debug deploy again:
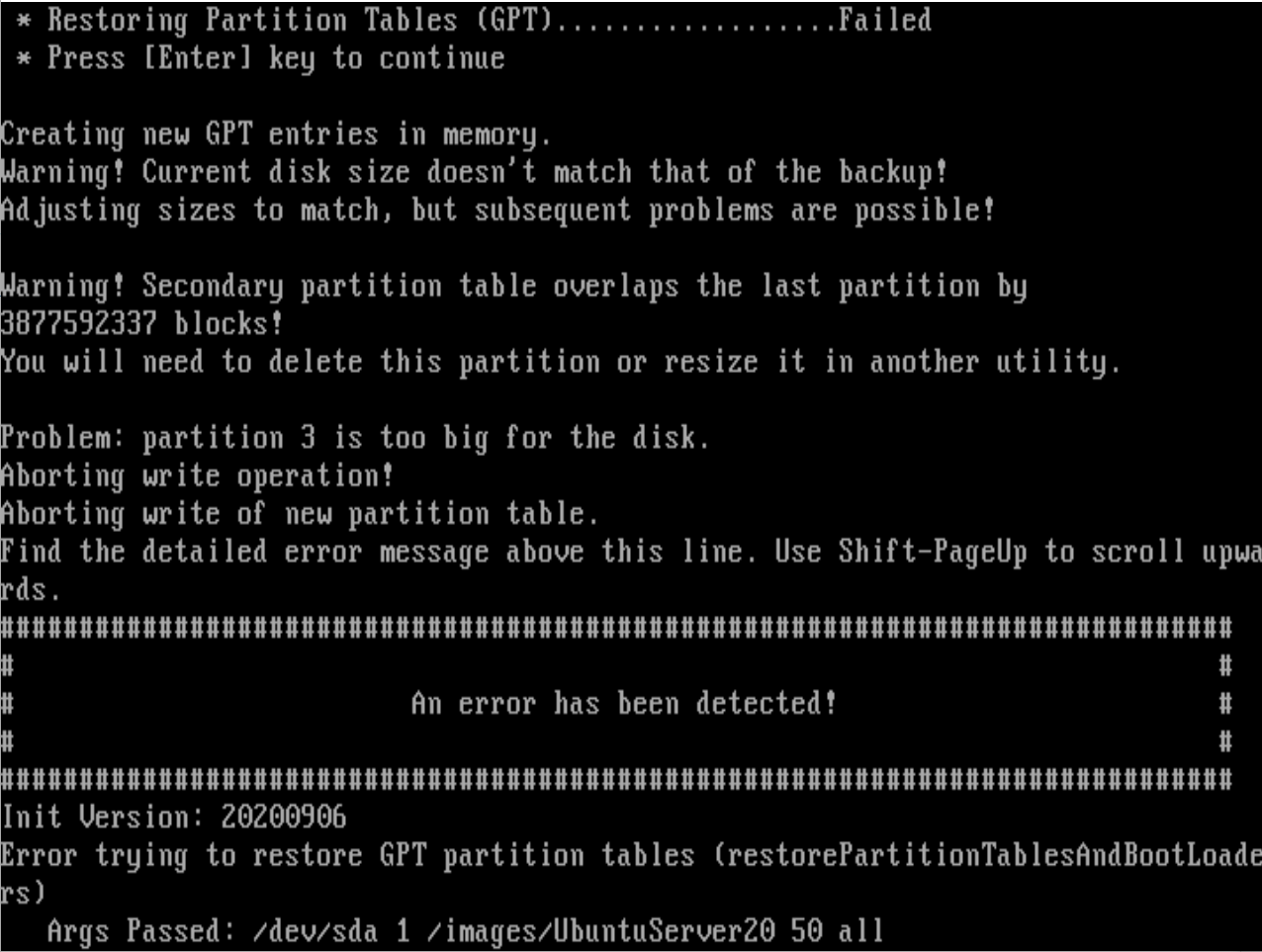
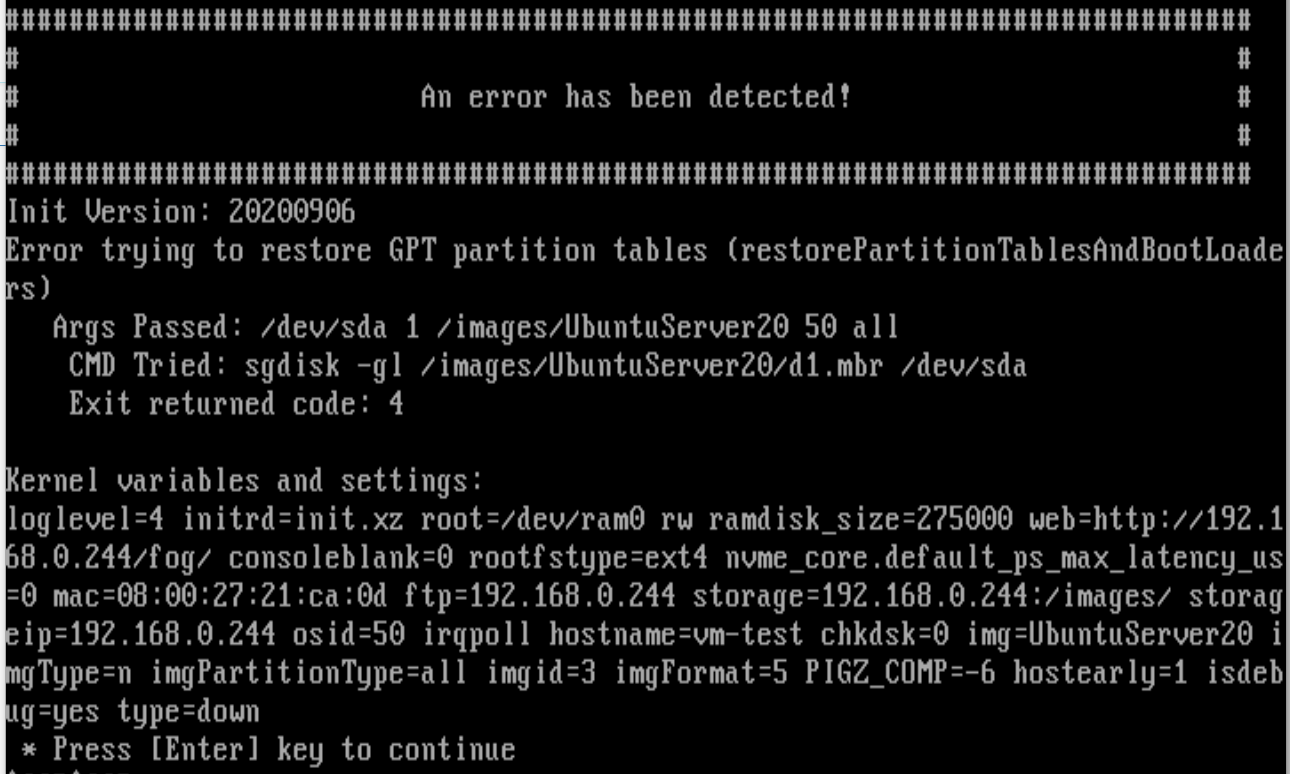
Then I delete the HDD in the VM and create a new with 25GB … same error.
-
@seppim OK, let us take a look at the partition table. Post the contents of the text file
/images/UbuntuServer20/d1.partitionshere in the forums. In that same directory you might have another file calledd1.minimum.partitionsand If so post the contents of that too. -
@sebastian-roth Thank you … here are the contents:
d1.partitions
label: gpt label-id: 01BDEC12-F9A1-4F00-BFC2-2B10AFF0D320 device: /dev/sda unit: sectors first-lba: 34 last-lba: 3907029134 sector-size: 512 /dev/sda1 : start= 2048, size= 2048, type=21686148-6449-6E6F-744E-656564454649, uuid=9B59A7D0-D660-42E9-9098-CF8A334905E2 /dev/sda2 : start= 4096, size= 3888156672, type=0FC63DAF-8483-4772-8E79-3D69D8477DE4, uuid=84C5FC93-D8A6-4B0A-B7CD-62C86A9A4232 /dev/sda3 : start= 3888160768, size= 18868224, type=0FC63DAF-8483-4772-8E79-3D69D8477DE4, uuid=B2ED86A4-3D80-402F-8C38-3A5EA00C33A0d1.minimum.partitions
label: gpt label-id: 01BDEC12-F9A1-4F00-BFC2-2B10AFF0D320 device: /dev/sda unit: sectors first-lba: 34 last-lba: 3907029134 sector-size: 512 /dev/sda1 : start= 2048, size= 2048, type=21686148-6449-6E6F-744E-656564454649, uuid=9B59A7D0-D660-42E9-9098-CF8A334905E2 /dev/sda2 : start= 4096, size= 852852, type=0FC63DAF-8483-4772-8E79-3D69D8477DE4, uuid=84C5FC93-D8A6-4B0A-B7CD-62C86A9A4232 /dev/sda3 : start= 3888160768, size= 18868224, type=0FC63DAF-8483-4772-8E79-3D69D8477DE4, uuid=B2ED86A4-3D80-402F-8C38-3A5EA00C33A0 -
@seppim This is the partition table you posted earlier from the Ubuntu system directly:
Device Start End Sectors Size Type /dev/sda1 2048 4095 2048 1M BIOS boot /dev/sda2 4096 2101247 2097152 1G Linux filesystem /dev/sda3 2101248 20969471 18868224 9G Linux filesystemWhile the information of the first partition (sda1) matches the later ones don’t. Size of sda2 and therefore start of sda3 are way larger than what you posted before.
Let’s do the math: In the header you see
last-lba: 3907029134which essentially means the last sector on disk. 3907029134 * 512 byte sector size / 1024 / 1024 / 1024 / 1024 = 1.819 terabyte. -> This particular image was captured from a huge disk!There are two important things you need to know about:
- As of now FOG does not move partitions on the disk. So even if it can shrink sda2 in your case it won’t move sda3 forward. We are working on this restriction but it’s now in production yet. If you are keen to test what we have so far, let me know.
- FOG does not recognize LVM properly and I can’t promise you to work at all times. Proper LVM support has been discussed but we never got to implement that.
So I suggest you re-capture your image from the initial install (sda2 being 1 GB in size) so you can deploy that image again. As well you might think about your partition layout and using LVM. Do you use LVM for a particular reason?
-
@sebastian-roth Hi Sebastian,
ok, this is a little weird … I try to capture again the Ubuntu Server 20 from my Virtual Box. HDD size 10GB.
Not possible … seems not enough storage.
But there are 50GB free:
Fog server:
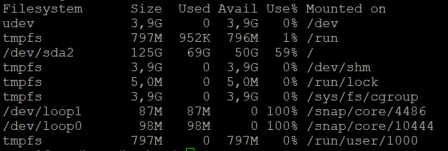
Capture error:
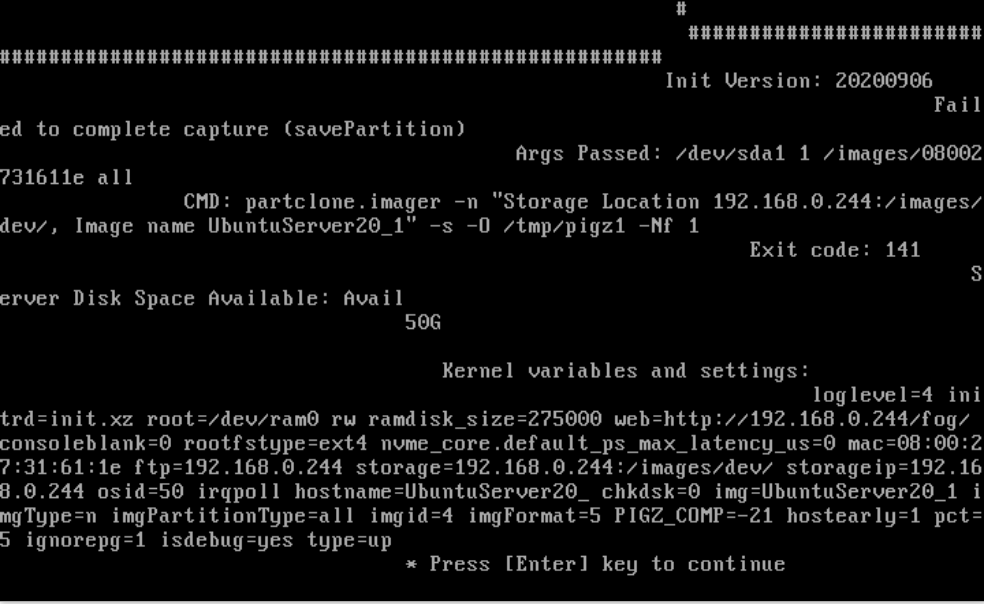
I´m not able to continue in debug mode … when I press Enter: nothing happens
-
@seppim This is just an idea, in the image definition UbuntuServer20_1 lower your image compression to 11 and see if you can upload then. If you are using zstd with a compression of 21 that will take a lot of RAM on the target computer.
Just out of curiosity how much RAM does this capture computer have?
Also looking at this I’m not sure why pigz_comp == -21 that just seems wrong. One might think that should be a positive integer value.
-
@seppim We are jumping from one issue to the next here and I am not sure I can follow.
The disk space available message at the end of this error is just a “blind hint” as we had users in the past that ran into an issue just because of disk space and we added this information to the error message. Doesn’t mean this is the actual cause in your case. Obviously not if your image is just around 10 GB. We would need to see if there is a preceding error. Best if you schedule the capture as debug and when you get back to the shell after the error you should find some information in
/var/log/partclone.log(on this host you capture from).There is more I find strange in this picture. Why is it using
partclone.imagerfor/dev/sda1? That would mean FOG cannot detect the filesystem on this partition. Shouldn’t that be the VFAT/FAT32 formated UEFI boot partition? -
@sebastian-roth Hello,
capture is now running … sorry, guess it was my fault?
I thought to use the latest kernel … but the list in the kernel module is not sorted by the newest. So I install 4.19.143 … I see this now and install now 5.6.18
I also set the compression back … its now capturing!
Sorry for the second issue … I try to capture and deploy on the physical and virtual PC and check if with multicast the problem stil exists (physical is resizing and virtual continue deploy)
-
@sebastian-roth ok, deploy is now running.
To set the timeout from 10 to 300 helps. The VM is waiting while the physical PC resizing /dev/sda2.
PC: 250GB HDD
VM: 10GB HDDBoth booting after deploy! Great
-
@seppim Unfortunately you changed 2 things at the same time so its unclear what fixed the partclone.imager problem. The kernel updates should have only have addressed new hardware.
Would you mind making a second test capture (to a new image definition) with the compression set back to 21 with the 5.x kernel installed. This is a unique error and we need to find what really fixed the problem. As you follow Sebastian’s debug test. You are not the first person to hit upon this issue.
Also how much ram is installed in this computer? 4GB?
-
@george1421 Hello!
Sure, no problem … from which PC you need to know the RAM?
Master VM: 1024MB
FOG server in Hyper-V: 2834MBI try to capture again.
edit:
yes, error:
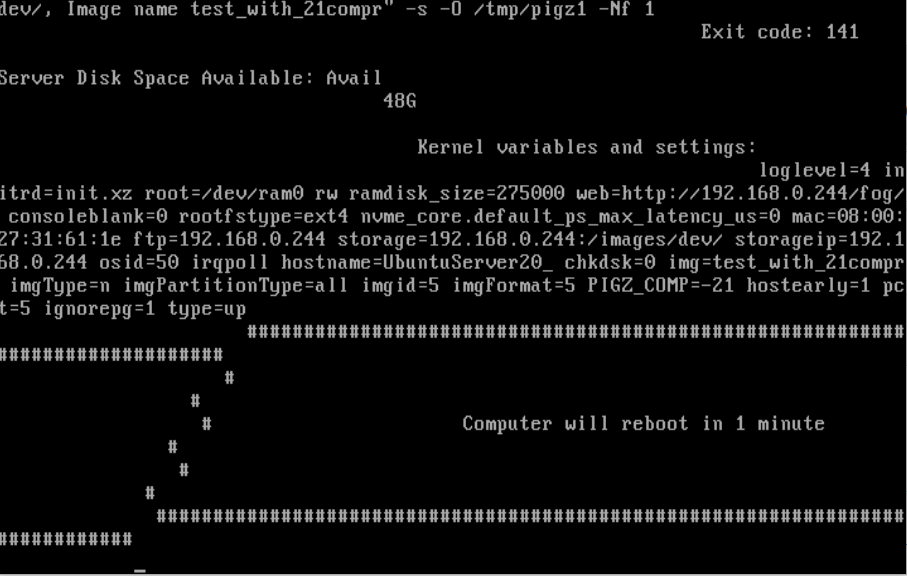
edit 2:
I set the Compression back to 18 … then he start capturingedit 3:
until compression 20 its working here … 21 and 22 throw erroredit 4:
no, after some time, he reboots … maybe running out of memory … but now error while startup the capturing -
@seppim Ok from your testing with 1GB of ram any compression over 19 with a 30GB (data) capture size it fails.
The issue with zstd compression (not an issue but a fact) is that zstd is a very good data compressor but it takes more RAM with the higher compression values. This is because it needs to buffer more of the image into memory to be able to sample more data to squeeze it down. My bet is if your pxe booting system would have 4GB of ram this issue would not appear at the compression of 21.
We are all learning here too, that is why its important to have people like you willing to help find the problem for the next guy.