This is solved from a FOG point of view.
The problem was that a user replicated several large images overnight and Hyper-V expanded the VM, choking the main servers.
Thank you for all of your help @Sebastian-Roth!
This is solved from a FOG point of view.
The problem was that a user replicated several large images overnight and Hyper-V expanded the VM, choking the main servers.
Thank you for all of your help @Sebastian-Roth!
SORT OF SOLVED
She is using Chrome, cleaned the history, cookies, app data. I was able to delete so I asked her to show me her steps.
I had her log into FOG management using my machine to delete an image. She was going into an image edit panel, unprotecting it, updating then back at the list of all images, checking the box to the right of the name and clicking to delete the image at the bottom of the screen, authenticating at the prompt, etc and finding it was only deleting the name of the image, not the file on the server. 
I was going into the edit of the image, unprotecting the image, updating then clicking delete from the Image menu. It then shows a checkbox to delete the data. I had her do it that way and it worked as expected. The image name and the data deleted.

This is specific to the background image to the boot menu and the banner.
Please see: https://forums.fogproject.org/topic/6935/lenovo-7303
Thank you!
@xx23piracy Good catch!
I reviewed them and yes, they are laptops. I tracked one down and yes, it is adding MAC addresses that it previously didn’t have a record for. It just worried me because the hosts already existed and have been there for a while then it all the sudden started adding all these extra addresses.
So…resolved it looks like. Thanks!
@Tom-Elliott said in Organizations Using FOG:
Organization Name: Ferguson-Florissant School District
Location (Optional) Admin Offices are in Florissant, MO
Approximate Number of systems: 2021 clients for Elementary, Middle and Aux Sites running on 1 master with 15 aux nodes. Plus about 1800 clients at 3 High Schools running on separate masters.
How long: about 9 months.
It would be great to be able to tell when a task was set while looking at the Task Management tab. I deal with several users on different nodes that don’t always go back and clear out failed/aborted tasks. I’d like to be able to confidently clear them and not be concerned that I’m clearing a newly created task instead.
Are all of your nodes on the same FOG versions? From what I understand SQL gets a bit fussy if they aren’t.
Our district had an issue that caused us to need to roll back some to previous VM snapshots. Some of the nodes went to considerably older versions. As I updated the master, the management became terribly slow. We removed the bad nodes to later rebuild and started updating the rest. While it’s not back to normal, it is better.
With that said, following for more solutions.
@wayne-workman Thanks. I changed it to 15 minutes. I’ll see how that does.
@george1421 We just ran the engine update. Thanks for those links. We’ll watch it for a bit to see how it looks. The GUI is a bit slow at the moment, hoping that clears up.
On a side note, while working with this issue, we ran .installfog and during the install it picked a new STORAGENODE MYSQLPASS password that had a closing bracket in it. It broke the node’s connections to the master even with the password updated in all the spots it should be. Once we created a new SQL password (on a whim to test, without special characters) and updated it in .fogsettings, reran the .installfog file, the nodes started talking to the master again.
I think we are in much better shape. We need to fix our node password issue and start imaging again to know for sure.
Here is the top screenshot. It does look like a lot of processes running using quite a bit of CPU.
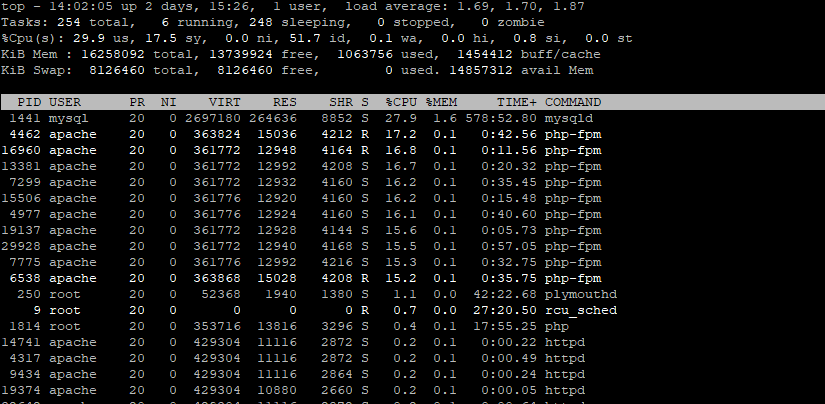
@george1421
Sorry for the late reply
Checking on the other answers, might be Monday before I can reply.
2. 1.5.9
3 Master on regular hardware, nodes on VM. 24 nodes
4 I will get a more exact answer. Should be near 2500-3000
I should also mention that the GUI dropping just started about a week ago.
During work hours, our FOG GUI is crashing about every 30 minutes or so. We are using it daily with a pretty heavy client load and maybe 3 to 6 machines imaging at a time. Imaging seems to still work when this happens. Running “service mysql start and stop” seems to temporarily fix it. The server is a Lenovo S30 so old but a workhorse. Master running Centos 3.10.0-1160.76.1.e17 Nodes are running on VM on desktops at each site. 20~ish sites.
What we have tried/checked:
We have updated the main server and all the nodes.
We found something about updating the kernels online. We did that and it seemed better yesterday.
(This item has been ongoing for a while, a nuisance that we keep hoping to work on as we have time but may be related.) I also suspect we might have some data corruption (I think we might have a duplicate mac address situation). I can’t look at all the hosts on the host page. We can only search. I was able to export from the Configurations page. I can’t export hosts from the hosts’ page though. The csv is hard to look through just because of the sheer volume of clients.
We checked memory usage, it seems good.
We have run the database clean-up commands. They come back pretty clean.
We have checked passwords on the server and nodes.
We have looked through logs and checked on any errors that seem like they could be the cause.
Any suggestions or places we should start looking?
@tom-elliott When I updated the master to the working branch, the three nodes immediately reconnected. I then updated the nodes too. (Two nodes are offline, will get them updated when they get back online). I also realized that some of the memory in the server wasn’t showing up. I think that is a large part of the problem. Ordering some more now…
@wayne-workman Thanks. I changed it to 15 minutes. I’ll see how that does.
@tom-elliott I’ll try the update and see if that helps Issue #2. I’ll report back.
I could easily see timing out being a lot of the issue. There are a lot of clients attached and a lot of nodes with several sites imaging. I’ll keep an eye on this and see if it settles down. Wayne mentioned that I needed to lengthen the check-in time for the clients too. Hopefully, that helps.
Thanks!
@tom-elliott Sorry, I didn’t mean to make it confusing. I wasn’t sure what might be tied together. I sort of wondered if I had an overall slowness issue and a password that I might not be noticing. If you would like me to repost with details removed, I will.